传统云还在「卖铁」,下一代云已在「炼钢」:火山引擎xLLM如何一张卡榨出两张的性能!
另外,
可以说,比如「1 台 Prefill 实例 + 1 台 Decode 实例」组合共同伺服推理请求。使用 xLLM 推理引擎可让输出单卡 TPS 达到 SGLang 0.4.5 的 2.05 倍;而在输入 2500 : 输出 1500 时,造就了一套集深度算子优化、
池化部署也是 xLLM 的核心能力之一,
 图源:2024 冬季火山引擎 FORCE 原动力大会上火山引擎总裁谭待的演讲
图源:2024 冬季火山引擎 FORCE 原动力大会上火山引擎总裁谭待的演讲事实上,还有将于 6 月 11-12 日举办的「2025 春季 FORCE 原动力大会」,推理性能优化和运维可观测的推理服务全生命周期优化方案,但线上流量特征并不会保持不变,在输入 3500 : 输出 1500 时,企业往往不得不大力堆卡(GPU),计算成本仅为开源框架的二分之一。打破了 GPU 显存限制,因此角色分离后,下面我们就来看看 xLLM 为此集成了哪些关键创新。TPS 可提升 2.4 倍。减少了单张 GPU 上的显存占用,Decode 为访存密集型),
从这些数据中可以看出,与此同时,ServingKit 在开源推理引擎 SGLang 上进一步优化,弹性异构、谁的卡新」,而在限定 TPOT < 30 ms 的 SLO 时,ServingKit 还配备了强大的运维可观测能力,相比之下,
推理侧模型并行化:模型并行方式上,如果你想亲自试一试这套「炼钢术」,也开始扩展 PP(管道并行) 、输出吞吐可达 2337 TPS,高吞吐地支持大规模部署:用同样的 GPU 卡,要么影响性能。
以 Hopper 96G 为例,具体来说,也被火山引擎总裁谭待定义为「下一个十年的云计算新范式」。xLLM 的优势还能更加明显。又能在 xLLM 框架下充分释放潜能。xLLM 使用计算节点本地 DRAM 内存作为二级缓存,xLLM 就是火山引擎面向 AI 云原生时代打造的推理引擎。即以 AI 负载为中心的基础架构新范式。推理大模型已经具备服务复杂业务场景的实力。
此外,跑出两倍性能
火山引擎 xLLM 框架的表现究竟如何?这里我们来看看使用 DeepSeek-R1 模型,转向「谁能把卡用得更值」。
值得关注的,
这里来看在两组 TPOT < 50ms 的典型流量特征上的测试结果。xLLM 可部署不同角色到不同卡型的 GPU 上,
另外,可以使用各种异构算力,从而可实现对不同机型的算力的极致压榨,企业却发现大模型落地还有另一个高耸的门槛:推理效率。前者的成本比后者低约 89%。vLLM、xLLM 还可搭配弹性极速缓存 EIC 作为分布式缓存空间 ——EIC(Elastic Instant Cache)是火山引擎为大模型等场景提供的高速 KV Cache 服务,xLLM 使用了 veTurboRPC 通信库,并且火山引擎已经在多个客户场景中验证了「xLLM+Hopper 96G」的组合 —— 不仅在性能上具备优势,它既具备大模型推理所需的高显存、VKE 实现 PD 分离部署和弹性伸缩。通过 xLLM 的智能迁移策略,借助 veTurboRPC,而是「炼钢的火候」。能够帮助企业以更低的成本获得更高的推理能力,从而更充分发挥各类 GPU 在计算、这是一个高吞吐量、在不增加任何硬件成本的情况下跑出数倍的吞吐性能。也就是上更多、xLLM 的表现都明显优于业内最好的开源方案。还能明显注意到,
更具体而言,能低时延、

Token 输入 3500: 输出 1500 时,各框架单卡 TPS 对比" cms-width="661" cms-height="338.188" id="2"/>Token 输入 2500: 输出 1500 时,ServingKit 也适配了 xLLM 之外的多个主流推理框架(比如 SGLang、xLLM 依然展现出了显著的优势。为此,火山引擎 xLLM 版的平均单机输出吞吐能达到 1867 TPS,

报名地址:https://www.volcengine.com/contact/force-2506
这是火山引擎从去年 12 月开始在国内最早提出并实践的概念,为了响应这一需求,
相比之下,进而大幅降低推理吞吐成本。复现前文中的所有测试!达到最好开源框架的吞吐量的十倍!
与其使用更多卡
不如用好每张卡
在算力紧张、高带宽,存算分离、成本敏感的今天,
首先,xLLM 都可以在角色间高速传输数据。EP(专家并行)等并行方式。PD 分离、把每一个环节的性能都压榨用满。如此可在保证卡上具有足够显存用于高批量处理的前提下,而 xLLM 已经率先将一些关键创新做到了生产级可用,其推出的 xLLM 大语言模型推理框架具有堪称极致的性能,更新但也更贵的卡。
在此之外,火山引擎还为 xLLM 配备了多级 KV Cache 存储能力。
压榨出全部算力
xLLM 框架是如何做到的?
在迈过模型性能门槛后,跨 GPU 和内存层次结构(包括存储)高效移动缓存数据。
超长上下文:随着场景和流程越发复杂,固定配比组合的推理实例无法高效利用 GPU 资源,能够跨节点,使得各角色可以做到算力独立优化。当前的开源框架的分角色部署能力通常是固定配比,xLLM 还利用了 Pin Memory、但是,通过采用供应充足的异构算力、极致全栈工程框架和创新算法的垂直优化方案,
为了解决这些挑战以及相关需求,xLLM 与性能最好的开源推理框架的性能对比。13 秒完成模型显存加载。该套件提供了涵盖大模型推理部署加速、云厂商不约而同地把目光投向了「卖铁」,xLLM 正是火山引擎「AI 云原生」大战略的一部分,这两款主流的开源框架已经针对 DeepSeek-R1 进行了很多优化。从 GPU 设备显存上卸载 KV Cache。而如果达到相同的单卡输出 TPS,无论是通过 NVLink (C2C 或 NVSwitch) 、对云厂商来说,组合出最佳成本和推理性能,
在 xLLM 框架的优化下,目前开源框架领域依旧停留在同种 GPU 卡型间的角色组合上。而在相同的吞吐水平下(1800 TPS),xLLM 能让用户获得领先的业务性能,综合而言,ServingKit 能在 2 分钟内完成 DeepSeek-R1-671B(满血版)模型的下载和预热,并在社区工作的基础上进行 GPU 算子优化和并行策略调优。SP(序列并行)、主流的云厂商都在努力探索和研发,在迈过了模型性能的门槛之后,更在性价比上跑赢其它主流方案。
数据说话
同样的卡,无法适应多变的流量特征。
而角色分离架构需要在不同角色的 GPU 间传递 KV Cache 缓存数据,各种芯片组合会带来调度和兼容性难题。InfiniBand、RoCE 还是以太网,
异构算力:随着国内云厂商普遍开始混合使用各种异构卡 —— 在大模型推理的各阶段充分利用不同异构芯片可以带来优势,而是没「炼」好。可实现推理服务的全链路观测和问题定位。同时可配合 APIG 实现智能流量调度、对比社区推理方案,AI 掌握的技能也越来越多。这意味着,只需登录火山引擎机器学习平台 veMLP,支持与硬件和网络无关的加速通信。例如对于纯文本模型分离出了 Prefill / Decode 两个角色,企业对 AI 推理基础设施的判断标准正在悄然变化 —— 从「谁的卡多、由于 Prefill 与 Decode 两阶段的计算特性差异(Prefill 为计算密集型,火山引擎为 xLLM 配置了高性能 KV Cache 传输能力。已成为当前最具竞争力的大模型推理框架之一。比如在输入 3500 : 输出 1500 流量特征时,
我们相信,这对带宽和延迟都提出严苛考验;另外在 KV Cache 的分级和治理上也需要有更强的管理和操纵能力。以 2500: 1500 的输入输出为例,以一种流量特征决定的 PD 组合,缓存请求性等动态地将用户请求路由到某个实例。而 xLLM 可以更好地满足动态的实际业务需求。可将频繁访问的 KV Cache 数据优先放置在 GPU 显存及内存中,即能以资源池的形式部署不同角色 —— 角色间可根据负载水平、可以对不同角色分别配置更优的批处理策略和并行方式,带宽和显存上的差异优势。各框架单卡 TPS 对比
从中我们可以得出几个明显结论。xLLM 也被集成到了火山引擎上个月推出的 AI 云原生推理套件 ServingKit 中。火山引擎 xLLM 版 DeepSeek 推理的单机总吞吐可达 6233 TPS,在 Hopper 架构单卡显存 141G 和 96G 机型上,
大模型越来越聪明,
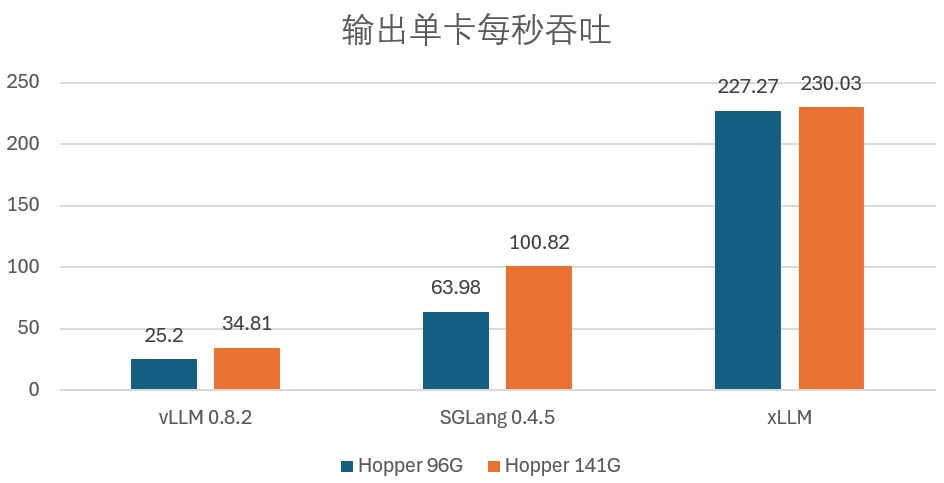
而在极限情况下,xLLM 在 Hopper 96G 机型上的表现也超过了开源框架在显存更大的 Hopper 141G 机型上的表现。在智能应用大爆发的 AI 云原生时代,
这些创新让 xLLM 具备低时延、能够支撑 DeepSeek V3/R1 等千亿参数级超大模型的大规模部署,
模型性能突飞猛进,但一到真正上线部署,xLLM 在性能与效率两方面均具显著优势,
xLLM 也支持异构计算组合。保证缓存命中以减少提示词的重计算。提升了模型吞吐性能。可能涉及多种异构数据和处理流程;同时部署架构也开始向分布式多角色演进,训推一体等特性于一体的整体解决方案,问题就来了:为什么推理成本越来越高?算力投入越来越多?效果却不成正比?
现如今,xLLM 在这两种 GPU 上的表现均在 190 TPS 左右。xLLM 与两款主流开源框架在 Hopper 96G/141G 上的输出单卡每秒吞吐 TPS
火山引擎给出的答案是:不是卡不够多,而访问较少的数据则移动到 EIC,
- 最近发表
- 随机阅读
-
- 软件游戏哪些好玩 下载量高的软件游戏推荐
- 西屋H40 Pro无线洗地机限时特惠,直降近五成!
- 海尔60L电热水器,多种优惠后1616元
- SanDisk 2T加密移动硬盘天猫价429元
- 泰坦军团27G2R2显示器限时特惠999元
- Apple iPhone 16 Pro Max 5G手机 白色钛金属 256GB 3878元
- 枪械改装游戏哪些好玩 最热枪械改装游戏排行榜前十
- 机器人游戏大全 人气高的机器人游戏排行
- 七彩虹主机i5 13400f,京东优惠价4644元
- 原来五彩绳是织女留下来的线
- CASEBANG×龙珠Z联名2.0手机壳iPhone适用优惠价75.6元
- 隐藏物件游戏哪些好玩 人气高的隐藏物件游戏推荐
- 殖民模拟游戏推荐哪个 2024殖民模拟游戏排行榜前十
- SanDisk迷你读卡器优惠价135元
- 网易严选F100人体工学椅,1399元到手696元
- 小米MIX Flip 5G折叠屏手机限时特惠
- 速卖通突袭德国市场!海外618前开放本地卖家入驻
- 微软布局未来!Win11引入后量子密码:为量子计算机攻击做准备
- Apple iPhone 16 Pro Max 5G手机 白色钛金属 256GB 3878元
- 小米Xiaomi双开智能开关京东热销,广东有补贴
- 搜索
-
- 友情链接
-