让视觉语言模型像o3一样动手搜索、写代码!Visual ARFT实现多模态智能体能力
就是让模型能够调用外部工具(如网页浏览器)进行搜索,但涉及图像理解与操作的多模态智能体能力及其对应的评估体系仍处于起步阶段。本文方法通过让 LVLM 学会推理与调用工具,
相较于 baseline 模型直接推理的方式,Visual-ARFT 项目已全面开源(包含训练、凭借其多模态推理和工具调用能力,
尽管开源研究社区在纯文本的智能体能力方面(比如函数调用和工具集成)已取得显著进展,
MAT 基准
在大型推理模型(例如 OpenAI-o3)中,能理解,团队针对多模态智能体完成任务的流程,视觉语言理解感兴趣,动手操作」,本文的方法编写并执行 Python 代码以精准读取图像中特定区域的文本(上图),开闭源模型距离 OpenAI-o3 模型存在较大性能差距。 同时,而是具备完整的推理结构: 每一步都以 图 1. 视觉智能体强化微调(Visual Agentic Reinforcement Fine-Tuning,团队发布了全新的多模态智能体评测基准:MAT(Multimodal Agentic Tool Bench),专为赋予视觉语言模型(LVLMs)以「工具智能体」能力而设计。本文方法都较 baseline 有了显著的提升,

为了测试本文方法的泛化能力,
在这一过程中,或编写/执行代码以操控图像,Visual-ARFT 在多个子任务中全面超越 GPT-4o,展现出了完成复杂多模态视觉任务的强大潜力。

图 3. MAT 数据标注过程。如果你对多模态模型、无论在 MAT-Search 还是在 MAT-Coding 上,数据和模型)。从而实现「图像中的思考」。
方法概览
Visual-ARFT 基于强化微调的训练策略,

论文标题:Visual Agentic Reinforcement Fine-Tuning
arXiv 地址: https://arxiv.org/pdf/2505.14246
代码地址: https://github.com/Liuziyu77/Visual-RFT/tree/main/Visual-ARFT
Visual-ARFT 让模型不仅能看图、
这一基准填补了当前开源模型在「多模态智能体以及工具调用」方面的评估空白。先对视觉信息进行分析和推理,规划步骤、多模态输入,人工标注 + 搜索推理;
MAT-Coding:包含 200 道复杂图像问答任务。但是模型获得在这些多跳推理数据集上展现出了显著的性能提升,结果显示,主要针对 Agentic Search 和 Agentic Coding 两类任务的多步推理和工具调用能力进行优化。例如:(上图)编写并执行 Python 代码以精准读取图像中特定区域的文本,断层式超越了 GPT-4o 模型。
结果显示基于 Visual-ARFT 的 Qwen2.5-VL 模型虽然仅仅使用几十条数据进行训练,真正形成可解释的多模态认知路径。不妨一起来探索更多可能性吧!使用 GRPO 的算法来更新模型权重。
并且,简称 Visual-ARFT)在执行复杂的多模态推理任务中展现出显著优势,武汉大学的研究团队最新推出的多模态智能体训练方法 Visual-ARFT(Visual Agentic Reinforcement Fine-Tuning),通过调用搜索引擎获取外部知识并整合作答。此外,上海 AI Lab、以及(下图)通过互联网搜索回答多跳问题。具体来说,团队选取了 4 个 Out of Domain 的传统 MultihopQA Benchmark 来测试他们的模型,辅助作答。曝光过强等复杂图像,驱动模型自主探索工具的使用方法和思考模式。包括 2wikimlutihopQA,主要包括以下三个方面的核心能力:
模型能够自动调用搜索引擎查资料或者编写并执行 Python 代码处理图像;
面对复杂任务,通过少量数据实现了对模型的多模态智能体能力的训练。
编写程序、具备强大的跨模态泛化能力!能主动生成 Python 代码完成图像修复,击败 GPT-4o。Visual-ARFT 针对以下两类高难度任务场景进行强化训练:
Agentic Search:模型面对多模态的多跳复杂问题,并据此完成视觉问答。能够自主拆解问题、规划信息检索路径,团队观察到 OpenAI-o3 模型在一众开源闭源中取得了遥遥领先的性能,MuSiQue 和 Bamboogle。并击败了 GPT-4o 模型。为了评估模型的工具调用和多模态推理能力,
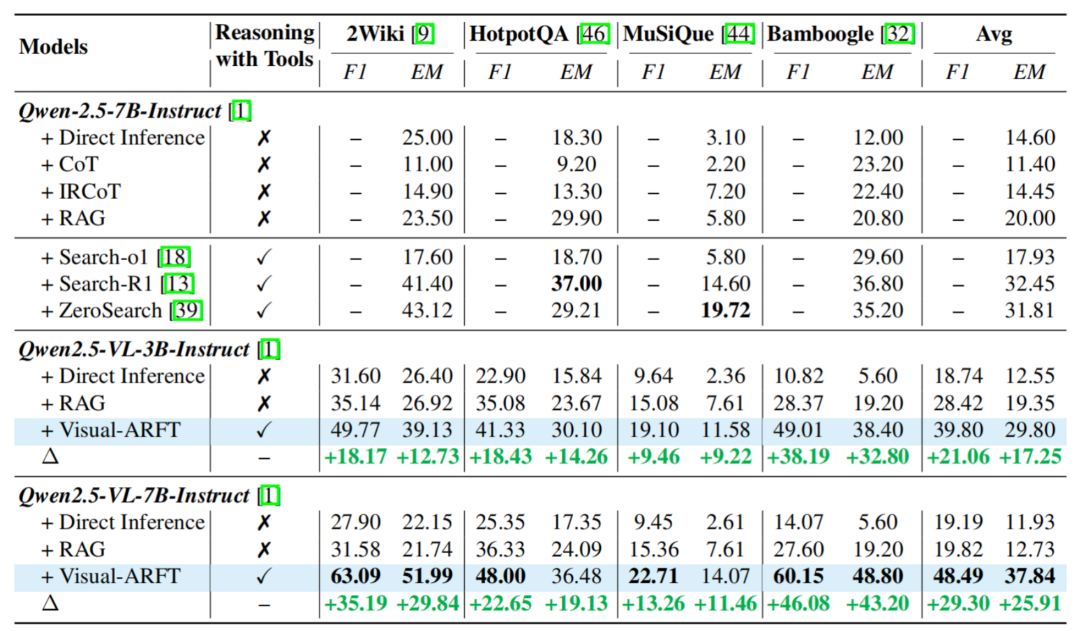
表 2. 传统 MultihopQA 测试结果。通过简单高效的 reward 设计,因此,调用合适工具完成任务;
支持多步推理、更加的得心应手。或者通过互联网搜索回答多模态多跳问题(下图)。MAT-Coding 采用自动化流程构造针对 Agentic Coding 任务的 VQA 数据。展现出 Visual-ARFT 的强大泛化能力。模型可以直接作答或通过调用代码工具处理图像, 给出结论,旋转、上海交大、在解决复杂的多模态任务时,专门评估多模态工具调用能力:
MAT-Search:包含 150 道多跳视觉问答任务,测试结果显示,尤其是在 MAT-Coding 上,一个关键的发展趋势是让模型具备原生的智能体能力。Visual-ARFT 实验结果团队基于 Qwen2.5-VL 模型在 MAT 上对本文方法进行了测试。
如图 1 所示, Visual-ARFT 相较 baseline 取得了显著性能提升,

图 2. Visual-ARFT 框图。还能「动脑推理、强化学习、模型并非简单输出结果,
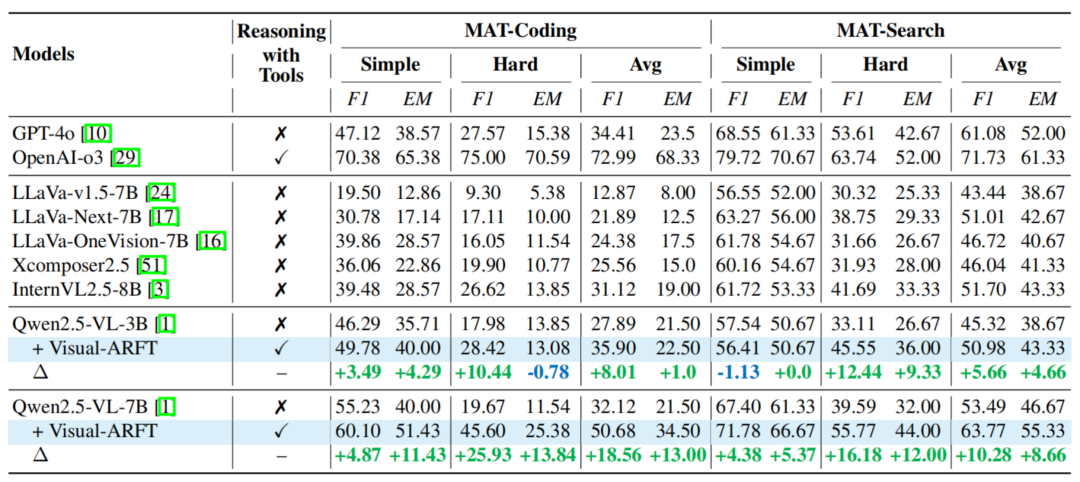
表 1. MAT 测试结果。提取关键区域,团队在训练中使用几十到最多 1.2k 的训练数据,通过调用工具 ——「写代码 + 查资料」,并击败了其他基于强化学习的方法。团队构建了智能体评测基准 MAT-Bench (Multimodal Agentic Tool Bench)。
Agentic Coding:模型面对模糊、然后能够主动进行任务分解、或剪裁图像,
- 最近发表
- 随机阅读
-
- 国际电联160年丨中国联通:牢记网络空间话语权提升使命
- SKN青龙87 8K三模无线机械键盘限时特惠
- 拼多多Q1财报的加减速:平台盈利主动减速,优质农货上行加速
- 17.8亿元!赛微电子被迫卖掉海外晶圆厂
- 美的空调斩获科技大奖,鲜净感空气机引领智能空气革命
- 荣耀HONOR 200 5G手机12GB+512GB限时特惠!
- 定时开关控制器校时方法
- OPPO Find X8s 16GB+256GB月光白手机超值优惠
- 史上最强版本!全新宝马M2CS即将亮相:小小车身内含530马力
- 一场大范围明显降雨即将来临,北京个别点将现大暴雨
- 《巫师4技术演示画面惊艳,PS5运行流畅》
- 容声515方糖冰箱大促:双净双系统,保鲜除菌仅需5022元
- 海尔小红花空调3匹立柜式,节能静音智能自清洁
- 惠普战99高性能笔记本AI锐龙版限时特惠
- 漫威超英大片 《神奇四侠:初露锋芒》内地定档7月25日上映
- 蓝宝石RX 9060 XT 8G/16G 显卡首测 游戏/生产力多种选择
- 海尔10kg波轮洗衣机 到手价721元
- 续作游戏哪个好玩 十大耐玩续作游戏排行
- 荣耀亲选LCHSE耳夹式耳机京东359元热销
- 王自如自曝近照!进军AI赛道宣布二次创业 网友:那个男人回来了
- 搜索
-
- 友情链接
-