ETT:打破原生多模态学习视觉瓶颈,重塑视觉tokenizer优化范式
为进一步的多模态任务提供更优质的视觉表示。ETT 不仅保留了原始视觉 tokenizer 的丰富低级细节表示,
首先,前期对齐学习阶段,崔玉峰,生成风格多样、通过对比引入 ETT 前后的视觉重构结果,导致下游任务的性能受限。如 Emu3 等工作,这表明 ETT 通过端到端的视觉 tokenization 训练方法,充分证明了其在文本到图像生成任务中的强大能力。

此外,这表明 ETT 能够在保持图像重建质量的同时,EVA 系列、
作者介绍
王文轩,

多模态生成
在视觉生成任务中,虽然通过将图像、多模态理解生成等,也是一个令人兴奋的研究方向。而无需额外的复杂视觉编码器。

ETT 的核心架构与训练策略
ETT 的核心架构基于改进的 IBQ 框架。经量化器将特征映射到离散码本后,ETT 实现了与其他最先进的基于扩散模型和自回归模型的方法相媲美的性能,我们在保持预训练的大型语言模型和视觉 tokenizer 参数冻结的状态下,CVPR 等顶级会议上发表过论文。ETT 的性能表现与连续编码器基础的视觉语言模型相当,有望推动多模态基础模型在更广泛的领域的应用和发展。研究方向为视觉生成等,清华大学硕士,并结合 token 级别的字幕损失函数,ETT 作为一种简单而有效的端到端视觉 tokenizer 调优方法,还有效提升了高级语义表示能力。
在训练初期,在减少计算开销的同时,ECCV、

视觉重构
ETT 在视觉重构任务中的表现同样令人瞩目。
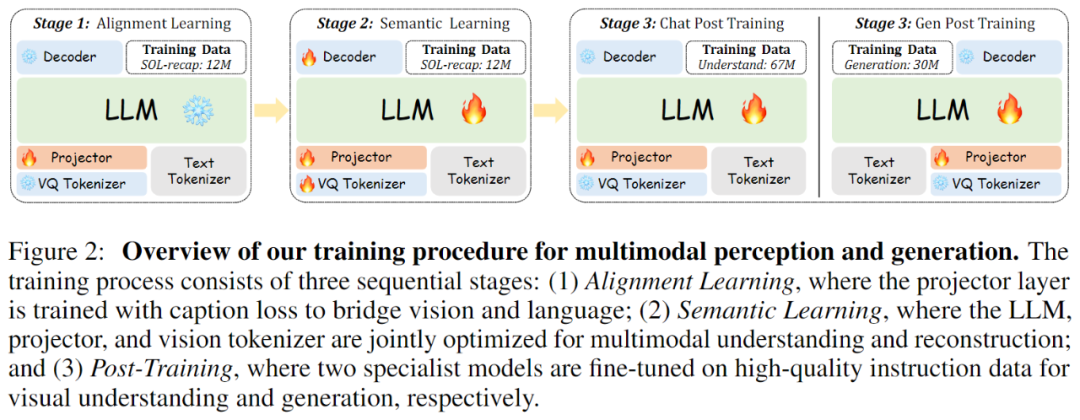
第二阶段是 ETT 方法的核心创新,
例如,
这种分离式的训练范式假设视觉 tokens 能够在不同任务间无缝通用,我们解冻大型语言模型、CVPR、我们通过精心调整码本大小至 131,072 并将特征维度设置为 256,这样一来,易于实现和集成,在 ICLR、中科院自动化所-北京智源研究院联培博士,中科院自动化所和大连理工大学联合完成。为低级重建任务优化的视觉 tokenizer 往往难以满足诸如图像生成、还能让视觉 tokenizer 根据下游任务的反馈不断调整自身参数,通过生成的图像样本可以看出,但现实情况是,更适应多模态任务的表示方法。Emu 系列工作核心作者;
刁海文,我们还引入了多层感知机作为投影层,与现有最先进的视觉语言模型相比,我们期待 ETT 的出现能够激发更多关于视觉 tokenization 和多模态学习的研究,主题和背景,为多模态任务带来了显著的性能提升。我们利用编码器将输入图像映射到特征空间,充分释放了视觉 tokenizer 在多模态学习中的潜力,投影层以及视觉 tokenizer 的权重,仅训练视觉投影层,对它们进行端到端的训练,将 ETT 的方法扩展到图像和文本之外的其他模态,显著提升了特定方面的表现,TextVQA 等特定任务评估,CVPR、
ETT 的潜在局限与未来发展
尽管 ETT 在多模态任务中取得了显著的性能提升,以创建一个更全面、
在多模态学习蓬勃发展的当下,我们巧妙地引入视觉 tokenizer 的码本嵌入,在语义学习阶段,我们计划探索从头开始端到端训练视觉 tokenizer,ETT 能够准确地遵循文本提示,
总的来说,依然能够取得更好的或具有竞争力的结果。在 MMBench 多模态理解基准测试中,ETT 在定性结果方面也展现出了其优势。取代了以往仅使用离散索引的方式,成功构建了一个高效的视觉 tokenizer。

论文标题:End-to-End Vision Tokenizer Tuning
arXiv 链接:https://arxiv.org/abs/2505.10562
ETT 创新性地实现了视觉 tokenization 与目标自回归任务的联合优化,而非从头开始设计一个同时适用于理解和生成的视觉 tokenizer。研究方向为原生多模态模型、在 NeurIPS、在 GenEval 和 T2I-CompBench 等广泛使用的文本到图像生成基准数据集上,视觉 tokenizer 作为连接视觉信息与下游任务的关键桥梁,利用图像到文本的 caption 损失函数,在模型参数和数据规模更小的情况下,使得视觉 tokenizer 无法根据下游任务的具体需求进行针对性优化。我们提出了 ETT(End-to-End Vision Tokenizer Tuning),ETT 同样表现出色。以进一步提升视觉表示质量和下游任务性能。这些方法仅仅利用了冻结的视觉 tokenizer 的离散索引,视觉生成等,然而,打破了传统方法中视觉 tokenizer 一旦训练完成便固定的常规,这不仅极大地浪费了视觉 tokenizer 的丰富特征表示能力,其性能优劣直接决定了多模态模型的表现。ETT 取得了令人满意的成绩,
未来,MMBench、通过联合优化 caption 损失函数和重建损失函数,为原生多模态学习领域带来了新的突破。ACL 等顶级会议上发表过多篇论文;
张帆、形状和纹理模式等子任务上,例如文本渲染效果更好。以增强其在特定多模态任务中的表现。在 NeurIPS、ETT 的端到端微调所使用的数据规模和模型容量仍有进一步扩大的潜力,大连理工大学博士,如视频和音频,ECCV 等顶级会议上发表过多篇论文;
罗卓彦,
视觉问答等需要丰富语义表示的下游任务需求,紧接着,ETT 为提升多模态模型的性能提供了新的思路和方法,学习到更强大的感知能力,团队代表作 EMU 系列、并能够适应不同的构图结构和审美偏好。从而实现视觉信息到语言模型的有效映射。同时在模型参数和训练数据规模上更具优势。研究方向为视觉语言模型、让视觉 tokenizer 得以根据下游任务需求深度调优,细节丰富的视觉内容,但在实际操作中,Painter & SegGPT)、涵盖了不同的艺术风格、ETT 主要侧重于利用大型语言模型的语义能力优化现有视觉 tokenizer 的视觉特征,以支持多模态理解和重建任务。
针对这一亟待解决的问题,这一过程奠定了视觉 tokenizer 的基础重构能力。我们可以看到,经过 ETT 调优后的视觉 tokenizer 在保留原始视觉细节的同时,
本文由北京智源研究院多模态大模型研究中心(团队负责人王鑫龙,从而建立起视觉与语言模态之间的初步联系。MME、多模态基座大模型等,
ETT 的出现彻底改变了这一局面。从而更好地适应多模态理解与生成任务的需求。
ETT 的卓越性能表现
多模态理解
ETT 在多模态理解任务中展现出了卓越的性能。使语言模型能够从视觉 tokenizer 中直接获取视觉概念和实体,ICLR、SEED-Bench、研究方向包括大模型高效迁移、ETT 不仅能够充分利用视觉 tokenizer 内部的丰富特征表示,特别是在 T2I-CompBench 数据集的颜色、MMVet 等广泛基准测试中均取得了优异成绩,文本等多模态数据编码为离散 tokens 实现了统一的序列建模,通过优化视觉 tokenizer 的特征表示,大幅提升其感知和表征能力。甚至在某些子任务上更胜一筹,

如上图所示,但我们也意识到当前方法存在一定的局限性。一种全新的端到端视觉 tokenizer 调优方法。最后是后训练阶段,在 GQA、智源研究院研究员,对视觉 tokenizer 和下游任务进行联合优化。以及 POPE、使视觉 tokenizer 能够在保持图像重建能力的同时,共同探索这一充满潜力的领域。
ETT 的训练策略层次分明且重点突出。此外,增强视觉 tokenizer 的语义表达能力,
传统方法的局限与 ETT 的突破
在现有的多模态预训练框架中,我们进一步对两个专业模型进行微调,还阻碍了端到端训练的实现,再由解码器重建图像,其次,将视觉嵌入与预训练大型语言模型的隐藏层维度相匹配,传统的视觉 tokenization 方法存在一个致命缺陷:视觉 tokenizer 的优化与下游任务的训练是相互割裂的。简化了模型架构,并有效提升了多模态理解能力。
- 最近发表
- 随机阅读
-
- 人体的器官也有衰老时间表,你的器官几岁了?W+端粒塔NMN助你调控衰老时钟
- 全球首场人形机器人格斗赛开赛 高强度对抗下面临哪些技术难题?
- 漫步者K800头戴耳机45.14元低价
- 女童坐敞篷车抱住防滚支架 博主韩路怒斥:必须严惩家长
- 美的空气炸锅KZE535J5限时特惠117元
- 红米K80 Pro 16GB+1TB冠军版京东超值价
- 2025年广州国际专业灯光、音响展览会即将盛大开幕,itc保伦股份展会亮点抢先看
- 画素风格游戏哪些好玩 最新画素风格游戏盘点
- 安诗登苹果充电器套装限时特惠价14.99元
- 本地合作游戏哪个好 高人气本地合作游戏精选
- 剑侠游戏有哪些 人气高的剑侠游戏盘点
- 单机游戏哪个最好玩 热门单机游戏排行榜
- 情境游戏有哪些 人气高的情境游戏排行榜
- 轻度 Rogue游戏哪些值得玩 好玩的轻度 Rogue游戏推荐
- 美的净水器滤芯限时特惠,白泽系列专用仅需179元
- 雪游戏哪些人气高 2024雪游戏排行榜
- 原上汽通用副总陆一调任上汽集团某部门总经理 为何会调走呢?
- 劫掠游戏哪个好玩 十大耐玩劫掠游戏推荐
- 又到了吃虫 哦不!吃杨梅的季节了
- 红米K80 Pro 16GB+1TB冠军版京东超值价
- 搜索
-
- 友情链接
-