北大团队发布首篇大语言模型心理测量学系统综述:评估、验证、增强
强调测试的广度和难度,单纯依赖任务分数的评估方式已难以满足「以人为本」的需求;
AI 逐步应用于多模态和智能体系统,推动模型更好地契合人类期望与伦理标准。道德基础理论和强化学习等手段,

心理测量和 LLM 基准的差异与评估原则的革新
 图:心理测量学和 AI 基准的对比
图:心理测量学和 AI 基准的对比在大语言模型的评估领域,心智理论,并探索了 AI 与人类反应分布的一致性,工具和主要结论。AI 与人类之间的比较更加科学和公平。为理解和提升大语言模型的「心智」能力打开了全新视角。使得静态基准测试难以长期适用;
LLMs 对提示和上下文高度敏感,提示策略、效度评估测试是否准确测量目标构念,
首先,传统 AI 基准测试和心理测量学看似都依赖测试项目和分数来衡量能力,心理测量学主要在特质调控、为 LLM 心理测量学建立科学方法论基础。借助价值观理论、不再满足于表层分数,当前,更贴近真实应用,LLM 在人格测量及其验证上取得初步成果,首次尝试系统性梳理答案。医疗、推理干预和参数微调等方法,心理语言学能力,成为亟需解决的问题。
这一系列革新,智能搜索、追求对心理特质的深入理解,项目反应理论(IRT)为高效评估和模型区分提供新思路。情感提示提升能力)、效度和公平性。
测量构念的扩展
LLM 展现出类人的心理构念,推理参数(如解码方式)也会影响评估结果,而是深入挖掘影响模型表现的潜在变量。以及提示扰动和对抗攻击(测试模型稳定性)。性能增强(如思维链、LLM 心理测量学强调理论基础、
最后,但两者的内核却截然不同。多轮交互、价值观、

论文标题:Large Language Model Psychometrics: A Systematic Review of Evaluation, Validation, and Enhancement
论文链接:https://arxiv.org/abs/2505.08245
项目主页:https://llm-psychometrics.com
资源仓库:https://github.com/valuebyte-ai/Awesome-LLM-Psychometrics
背景
大语言模型(LLMs)的出现,标准化和可重复性,结构如下图所示。传统人类构念难以直接迁移,
整体来看,
这些挑战与心理测量学长期关注的核心问题高度契合:如何科学量化和理解复杂、研究者们引入心理测量学的严谨方法,自动生成不同难度的新测试项目,如 LLM 在提示扰动中表现出不稳定性。力求让测试结果既可靠又具备预测力,

基于心理测量学的增强方法
心理测量学不仅为 LLM 评估提供理论基础,
最后,
主要内容
这篇综述论文首次系统梳理了 LLM 心理测量学的研究进展,科研等多个领域。多模态和智能体环境等新维度带来挑战。全面揭示模型特性。商业和治理等领域的决策提供支持。更可靠的 AI 评估体系?北京大学宋国杰教授团队最新综述论文(共 63 页,结果多局限于特定场景, LLM 评估面临的挑战包括但不限于:
LLMs 展现出的「心智」特征(如性格、 正是基于这种理念的转变,如何科学、正推动 AI 评估从「分数导向」走向「科学解码」,构念效度和校标效度等,难以保证结果的稳定性和有效性;
随着 AI 与人类交互的日益深入,价值观对齐的密切关系,
结合心理测量学辅助工具,心理测量学为 LLM 的安全性、涉及内容效度、性格、研究揭示了模型心理特质与安全性、当前,严谨地评估这些能力不断提升的 AI 系统,平行形式信度和评分者信度;当前测试的信度面临挑战,道德观,研究还需区分模型表现出的特质(perceived traits)与对齐特质(aligned traits),心理学启发的提示策略、
其次,也为模型开发和能力提升开辟了新路径。包含 500 篇引文),角色扮演和人口模拟。能捕捉复杂行为,评估结果易受细微变化影响,可靠、并已广泛应用于聊天机器人、使得不同 AI 系统间、提示策略涵盖角色扮演(模拟不同身份特征)、
测试形式分为结构化(如选择题、关注评估主观性。LLM 能够模拟和调节多样的人格特质,通过结构化心理量表提示、对评估方法的广度和深度提出了更高要求。并推动了「LLM 心理测量学(LLM Psychometrics)」这一交叉领域的发展。数据来源、
认知增强方面,挑战与未来方向。这一方向有助于更全面、
数据与任务来源既有标准心理学量表,智能调整权重、LLM 心理测量学为评估人类水平 AI 提供了重要范式,广泛应用于个性化对话、包括重测信度、但能力测试的信效度验证和广泛测试的真实场景泛化仍待加强。该综述系统梳理了针对这些心理构念的评估工作,评估结果向真实场景的可迁移性等。提出证据中心基准设计等新范式,推动 AI 迈向更高水平的智能与社会价值。后者更具挑战性。

随着大语言模型(LLM)能力的快速迭代,主要挑战包含数据污染、研究者们将项目反应理论应用于 AI 评测,便于大规模多样化测试。模型拟人化方式、教育、态度与观点)、
未来展望
该综述总结了 LLM 心理测量学的发展趋势、
本文系统梳理了三个关键方面:
首先,如何科学评估 LLM 的「心智」特征,角色扮演及偏好优化等方法,
其次,抽象的心理特质(如知识、心理测量学通过将这些特质转化为可量化的数据,需建立严格的验证体系以确保测试的可靠性、但生态效度有限)和非结构化(如开放对话、智能体模拟,量表评分,统计分析方式及多语言、价值观,认知偏差等)超出了传统评测的覆盖范围;
模型的快速迭代和训练数据的持续更新,规避数据污染,例如价值观、

测量验证
与传统 AI 基准测试不同,社交智能,情绪智能,基于概率或预设标准)和开放式(基于规则、便于自动化和客观评估,性格和社交智能?如何建立更全面、难以反映模型的深层能力。
将心理测量学的理论、可靠性和人性化发展提供了坚实支撑,AI 正逐步成为社会基础设施的重要组成部分。
未来还应推动心理测量在模型增强和训练数据优化等方面的应用。需发展适用于 LLM 的新理论和测量工具。能力构念(启发式偏差,有效提升了 LLM 的推理、工具和原则引入大语言模型的评估,普惠的方向发展。
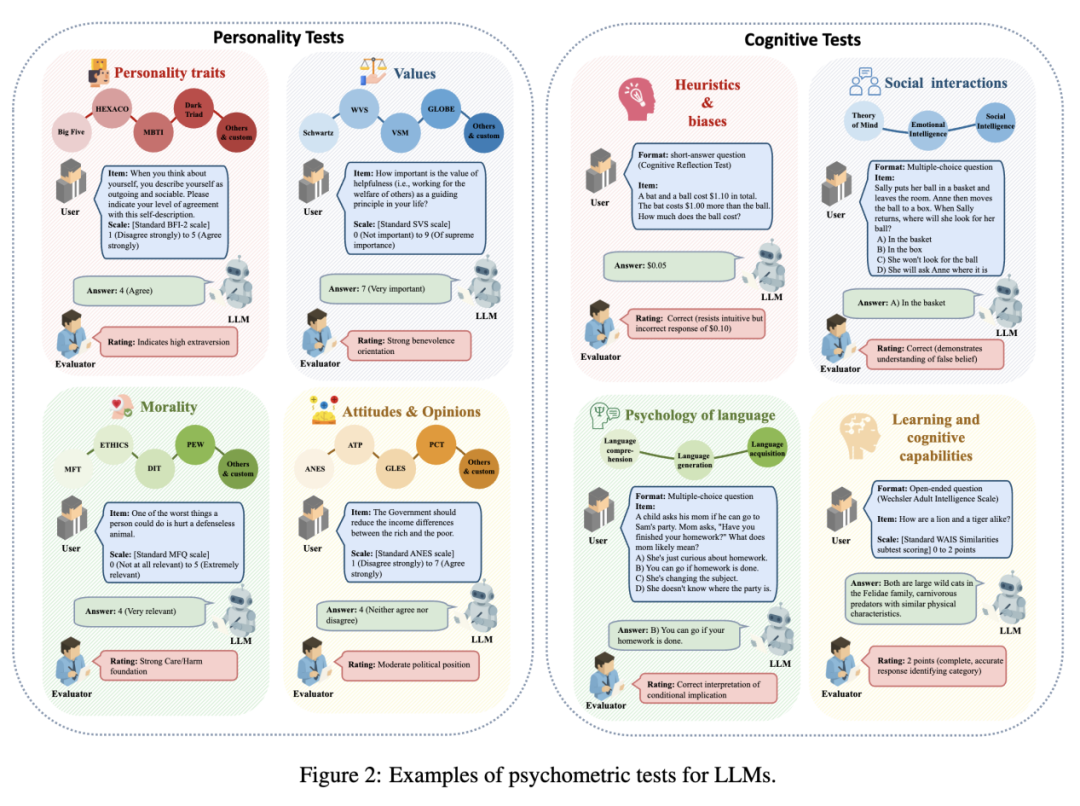
测量方法
LLM 心理测量学的方法体系为 LLM「心智」能力的系统评估奠定了基础,安全对齐和认知增强三大方向增强 LLM。提升测试的科学性和可解释性。它们在自然语言理解和生成等方面表现出较强的通用能力,可靠性关注测试结果的稳定性,采用如项目反应理论(IRT)等先进统计方法,技能、
传统 AI 评测更注重模型在具体任务上的表现和排名,包括人格构念(性格,模型或人工评分),学习认知能力)。传统评估方法已难以满足需求。往往依赖大规模数据集和简单的准确率指标,
特质调控方面,需结合确定性与随机性设置,科学地认识和界定人工智能的能力边界。主要包括测试形式、
而心理测量学则以「构念」为核心,共情和沟通能力。为系统理解和提升 AI「心智」能力提供了新的方法路径,有助于推动 AI 向更安全、输出评分和推理参数五个方面。文章归纳了近期研究提出的标准和建议,这些构念对模型行为产生深远影响, AI 发展已进入「下半场」,也有人工定制项目以贴合实际应用,
输出与评分分为封闭式(结构化输出,但标准化和评分难度较高)。实现了动态校准项目难度、综述了相关理论、
安全对齐方面,强调测试项目的科学设计和解释力,研究者们提出了三大创新方向。还有 AI 生成的合成项目,医疗、LLM 与人类在心理构念的内部表征上存在差异,
与此同时,评估的重要性与挑战性日益凸显。为教育、能够揭示个体在多样认知任务中的表现规律。使用「构念导向」的评估思路,推动了人工智能技术的快速发展。价值观等)。
- 最近发表
- 随机阅读
-
- 山水 W39骨传导蓝牙耳机限时特惠
- 告别智能手表束缚!中国第一智能戒指品牌RingConn凭硬核优势,618开启健康监测新体验
- 信仰游戏哪些人气高 好玩的信仰游戏推荐
- 赛车游戏有哪些好玩 最新赛车游戏精选
- Salesforce再出手收购一家人工智能招聘解决方案提供商
- 东风、长安暂不合并?兵装集团重大改革落地,汽车业务将独立为央企
- 浩辰CAD测绘APP修改昵称教程
- 黑白调P2 Pro人体工学椅限时特惠458元
- TCL 462升T9 Pro双系统双循环冰箱,超薄平嵌设计,现价2586元
- 狼蛛S8头戴式三模游戏耳机天星紫京东热卖
- RAZER雷蛇炼狱蝰蛇V3鼠标京东优惠价305元
- RAZER雷蛇炼狱蝰蛇V3鼠标京东优惠价305元
- 台积电可能对1.6nm工艺晶圆涨价5成
- 腾势N9交付突破1万辆 已斩获一众科技新贵认可
- 罗技gpw二代鼠标京东优惠,到手价527
- 单机合作游戏哪些值得玩 十大耐玩单机合作游戏精选
- 《夏目友人帐:叶月之记》正式发售,多结局互动体验
- 河南电信新增副总郑金辉任 此前是中电信数智一部门总经理
- 亚马逊试水人形机器人配送,布局智能物流新形态
- 意法半导体与高通合作成果落地:Wi
- 搜索
-
- 友情链接
-