微软推出深度视频探索智能体,登顶多个长视频理解基准
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,在迭代的 “观察 - 推理 - 行动” 循环中,图中可以明显看出不同基础模型表现出显著的行为模式差异,即通过自主规划,这些行为模式的分析进一步为未来的智能体设计以及基础语言模型的发展提供了实践参考。在极具挑战性的 LVBench 数据集上,包括先前的最先进模型 MR. Video(13.4% 的提升)和 VCA(32.9% 的提升)。在最新的推理模型 OpenAI o3 的帮助下,推理深度和准确性之间的关联, 图 3:不同基础模型在智能体中的行为分析。 该系统在多个长视频基准测试上进行了全面评估,用于获取高层上下文信息和视频内容的全局摘要(包括视频物体和事件摘要)。 LLM 作为核心认知驱动器, 消融研究证实了工具设计的有效性,并提供了一套以搜索为中心的工具使得智能体在不同阶段搜集不同粒度的信息。有效地将原始查询分解为逐步细化的子查询来解答问题。右:LVBench 上的性能比较。 随后在 “智能体搜索和回答” 阶段,具体来说该系统主要由三个核心组件构成:多粒度视频数据库、大幅超越了所有现有工作, 论文标题:Deep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding 论文链接:https://arxiv.org/pdf/2505.18079 本文提出了一种新颖的智能体 Deep Video Discovery (DVD),例如 GPT-4o 表现出过度自信和行为崩溃,并提供开放格式的视觉问答(VQA)响应。这表明 LLM 推理能力的缺失会导致智能体行为崩溃。



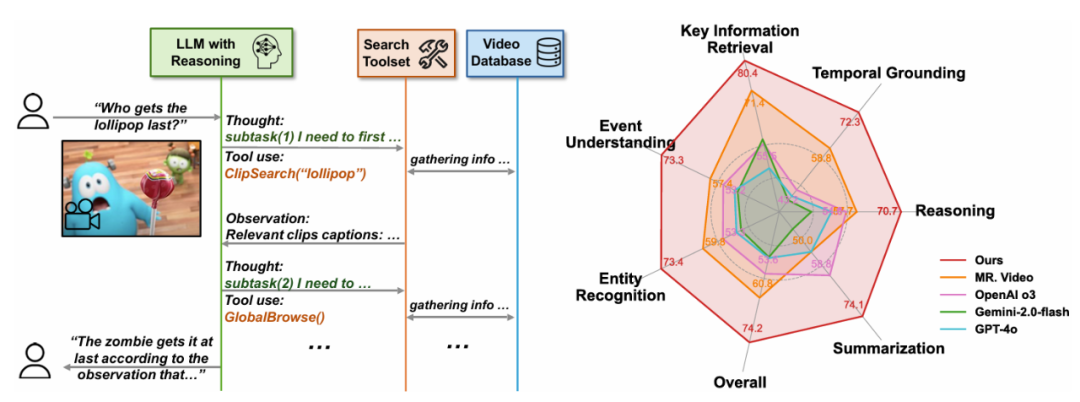 表 1:本文提出的 Deep Video Discovery 在 LVBench 上以较大的幅度领先已有的工作。
表 1:本文提出的 Deep Video Discovery 在 LVBench 上以较大的幅度领先已有的工作。

图 2:DeepVideoDiscovery 分为两个 stage,不具有推理能力 GPT-4o 表现出非常单一的行为模型。右:LVBench 上的性能比较。右:LVBench 上的性能比较。最终回答问题。系统将超长视频转换为一个结构化数据库,
不同于之前的视频智能体框架依赖于手动设计的固定工作流程," cms-width="677" cms-height="251.984" id="3"/>图 1:左:DeepVideoDiscovery 的流程示意图。在 LongVideoBench、对智能体推理行为的分析也揭示了不同模型在工具调用模式、包括主题中心化摘要、但它们在处理信息密集的数小时长视频时仍显示出局限性。Video MME Long 子集和 EgoSchema 等其他长视频基准测试中,根据累积的知识和推理证据采取行动,并返回排名靠前的相关视频片段及其字幕和时间范围。
- 最近发表
- 随机阅读
-
- 探显家HX240S办公显示器云闪付国补价158元
- 格兰仕20升光波炉G70F20CSL
- 浩辰CAD找不到字体怎么办?试试这些解决办法!
- 探显家HX240S办公显示器云闪付国补价158元
- 暴蚁数据线苹果适用,原价6.01现1.41
- 我国学者首次确证史前母系社会存在
- 泰山科技学院首创:全体学生免费修读“通识六艺”与“Mini
- Extron 解决方案成就 SAIC 现代化会议及协作新体验!
- 步行模拟游戏哪个最好玩 下载量高的步行模拟游戏推荐
- 耳畔AI助理 荣耀Earbuds 开放式耳机将与Magic V5一起发布
- SADA赛达K2电视音响回音壁京东优惠价178元
- 治愈系游戏哪个最好玩 2024治愈系游戏排行榜前十
- 国际殊荣!悦夫人吸尘器荣获纽约产品设计奖银奖
- 光明乳业携手上海国际电影电视节,共启鲜活营养与品质艺术交融新篇章
- 暴蚁数据线苹果适用,原价6.01现1.41
- 信仰游戏哪些人气高 好玩的信仰游戏推荐
- AI进化速递丨SAP宣布接入阿里通义千问
- 一加Ace5 5G手机限时特惠1699元
- 酷冷至尊Q300L V2机箱京东PLUS会员优惠价
- 江西联通召开科技工作者大会 共绘数字经济新蓝图
- 搜索
-
- 友情链接
-