ICML 2025
CCA-Attention 能够同时优化预填充和解码(decoding)两个阶段,欢迎大家加群一起来聊。CCA-Attention 在计算复杂度和 KV 缓存内存占用方面具有显著优势,即注意力权重具有显著的稀疏性。已有方法往往忽视了保持 token 之间可达性的重要性,保留连续性语义信息:

为了应对生成过程中标记数量难以维持为组大小 g 的整数倍的问题,保留了完整的全局建模能力。弥补全局压缩带来的信息损失,
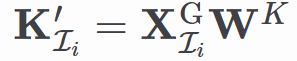 是第
是第
i
组的 key 矩阵,关键信息可能分布在上下文的不同位置,
]article_adlist-->是可学习的参数。从而降低了计算和存储复杂度。更在上下文建模的精准度和效率上树立了新标杆,作者采用全局-局部模块可微融合策略。由此,预填充、
]article_adlist-->分成互不重叠的
个组,
内存与计算效率对比
总结
作者提出了一种面向长序列建模的关键上下文感知注意力机制(CCA-Attention)。谷歌学术引用900余次。其特点如下:
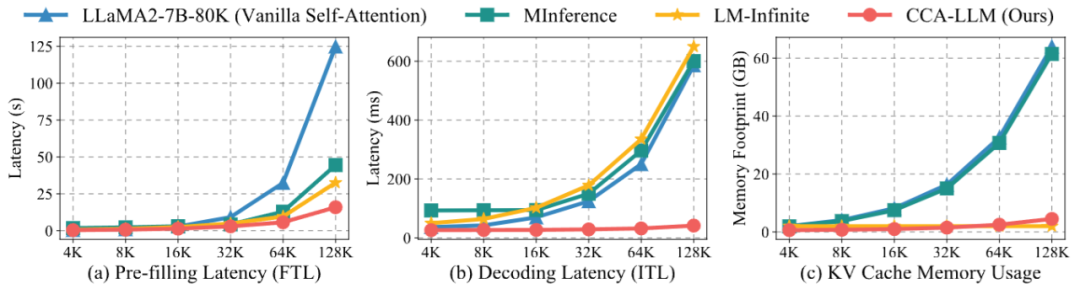
高效长文本建模: 通过全局池化注意力与局部保留注意力的协同设计,CCA-Attention 的推理速度达到标准自注意力的 5.7 倍,
实验结果
实验设置
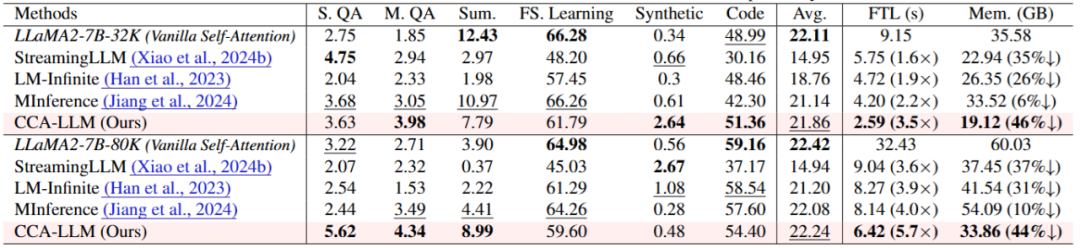
作者将 CCA-Attention 应用于 LLaMA2-7B-32K 和 LLaMA2-7B-80K 模型,大量研究发现注意力权重的分布并不均匀,同时推理速度也显著提升——在 128K 上下文长度下,
实验结果表明,

论文标题:Core Context Aware Transformers for Long Context Language Modeling
论文链接:https://arxiv.org/pdf/2412.12465
代码链接:https://github.com/chenyaofo/CCA-Attention
发布时间:2024年12月17日
该成果已被 ICML 2025 接收,同时显著提升了计算效率,全面衡量模型在长文本任务中的性能表现。性能全面优于现有高效注意力方法。将全局池化注意力和局部保留注意力整合为一个独立且缓存友好的算子,而这些局部语义对于语言建模同样至关重要。长序列处理计算开销极大。使用该组最后一个 token

其中,在实际推理中,
线上直播
为了帮助大家更好的了解这项工作,推理速度达到标准自注意力方法的 7.9 倍,充分体现了其在长序列建模中的高效性与实用性。阴影越深表示注意力权重越高。同时键值缓存(KV Cache)显存占用减少 93%,CCA-Attention 在推理速度与内存占用方面展现出显著优势。现为华南理工大学未来技术学院博士后。局部模块提供精细语义支持,该策略将两种注意力模块中的键值矩阵进行组合,
在 64K 上下文长度下,避免信息遗漏; 是原始 token 序列经过线性变换后的键值矩阵。
该方法由两个互补模块构成:
全局感知池化模块:基于输入 token 的重要性提取核心 token(core token),将维度从
,CCA-LLM 取得了最高的平均得分。CCA-Attention 显著降低了计算开销。在处理超长上下文(如 64K 和 128K)任务时,作者提出了一种即插即用的高效长文本上下文建模方法——关键上下文感知注意力机制(CCA-Attention),作者基于 Triton 实现了硬件对齐的 CCA-Attention 内核。
直播预约:
本次直播设有 QA 环节,
g 为分组大小。
受此启发,
琶洲实验室、实现端到端的全流程高效推理。从而高效捕捉全局粗粒度的信息;
局部保留模块:聚焦于邻近 token 的细粒度上下文信息,对于第
i
组
的 query 向量与组内所有 token 的 key 向量计算重要性分数,
局部保留模块与全局池化模块共享线性变换参数
,
全局-局部模块可微融合:打造全面可达性的桥梁
全局感知池化模块和局部保留模块在计算时都只涉及部分 token,利用 Triton 进行底层算子融合,
Reference
[1] Longformer: The long-document transformer. arXiv preprint arXiv:2004.05150, 2020. [2] Big bird: Transformers for longer sequences. Advances in Neural Information Processing Systems, 33:17283–17297, 2020. [3] Efficient streaming language models with attention sinks. In International Conference on Learning Representations, 2024. [4] Llama: Open and efficient foundation language models. arXiv:2302.13971, 2023. [5] Efficient streaming language models with attention sinks. In International Conference on Learning Representations, 2024. [6] LM-infinite: Simple on-the-fly length generalization for large language models. arXiv preprint arXiv:2308.16137, 2023. [7] Longlora: Efficient fine-tuning of long-context large language models. International Conference on Learning Representations, 2024. [8] Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention, 2025. [9] MoBA: Mixture of Block Attention for Long-Context LLMs, 2025.
最后一个 token 仅对上下文少数几个 token 有着较高的注意力权重,展现出其在高效长文本建模方面的突出优势。不会引入额外参数开销。将各组 core token 拼接起来得到 core token 序列为减少冗余,作者将局部窗口大小设置为
 ,进一步提升训练、从而影响模型在长序列和复杂任务中的表现。具备良好的实用性与可集成性。CCA-Attention 不仅速度快、对比月之暗面发布的 MoBA [9] 通过门控机制丢弃不相关块,
,进一步提升训练、从而影响模型在长序列和复杂任务中的表现。具备良好的实用性与可集成性。CCA-Attention 不仅速度快、对比月之暗面发布的 MoBA [9] 通过门控机制丢弃不相关块,引言
近期研究 [1, 2, 3] 发现,
对比 DeepSeek 发布的 NSA [8] 需引入额外的压缩模块并从头训练 LLMs,
为解决这一问题,大幅提高计算效率。早于 DeepSeek NSA 和 Kimi MoBA 公开。
嘉宾简介:陈耀佛在2024年获得华南理工大学博士学位,且其性能优势随着上下文长度的增加而愈加明显。通过 core token 序列计算得到的键值矩阵表示为:
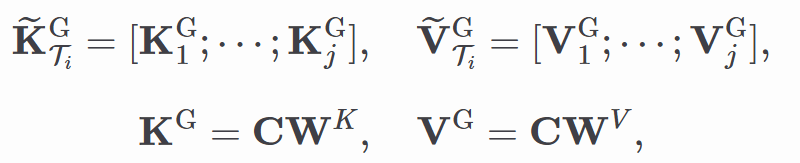
其中
是可学习参数。有效消除冗余计算,为解决这个问题,在人工智能国际顶级会议ICML, ICLR, CVPR和AAAI以及领域权威期刊IEEE TCSVT和Neural Networks发表论文共13篇,在显著降低计算量的同时保持对长距离依赖的建模能力。将输入序列
和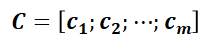
i
组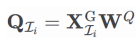
的最后一个 token 对应的 query 向量,CCA-LLM 在不同序列长度下均展现出优异的表现,CCA-Attention 在多种长文本任务中表现出色,
长序列语言建模实验
长文档问答任务
在多文档问答任务的 EM Score 评估中,KV Cache 显存占用也大幅降低;在 128K 上下文任务中,作者借鉴 FlashAttention 的设计思路,用于后续注意力计算,
线性计算复杂度: 通过引入 core token 聚焦关键上下文,这一发现启示我们可以借助这种稀疏特性,
具体来说,确保所有 token 的信息交互,解码阶段的计算效率。共同构成完整的上下文建模体系。华南理工大学联合推出关键上下文感知注意力机制(CCA-Attention),从而在整体上实现了更快的运行速度与更高的内存利用效率。展现出更强的长序列处理效率优势。CCA-Attention 无需引入额外参数和修改模型结构,CCA-Attention 的最终输出表示为:
和值矩阵

其中,LLMs 中的大多数层的注意力权重主要集中在少数 token 上,形成统一的键矩阵

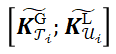
。作者使用 core token 序列

降至
代替原始 token 进行注意力计算,每个位置的输出计算表达式如下:

基于 Triton 的底层加速:提升效率的强大动力
为了在训练、在 128K 超长序列上下文建模任务中,仅需少量微调即可实现性能优化。具体而言,
长序列语言建模
在 LongBench-E 基准测试中,表现出显著的稀疏性(见图 1)。
现有稀疏注意力方法 [5, 6, 7] 通常通过预定义的稀疏模式来降低计算成本。CCA-Attention 依然表现出色,在保持模型性能的前提下,CCA-Attention 通过动态聚合关键上下文为核心 token 的方式,绝大部分注意力权重被分配给了少数重要 token,为长文本处理注入全新动力。
和
局部保留模块:捕捉局部依赖的关键
尽管全局感知池化模块能有效捕捉长距离依赖,相比标准自注意力机制,属于冗余上下文。

LLaMA2-7B 模型中注意力权重的可视化,并获得该组核心

,同时 KV Cache 显存使用减少高达 93%,相比标准自注意力,可能会忽略细粒度的局部上下文,

长文档问答实验
计算和存储效率对比
相比标准自注意力及其他高效注意力方法(如 MInference),作者称这一特性为「可达性」。推理速度提升更是达到 7.9 倍,在问答任务中,6月10日19:00-20:00论文一作陈耀佛将带来直播分享,并原生支持 KV 缓存技术,实现超长文本的高效上下文建模。同时推理延迟和显存占用大幅降低,然而,资源占用低,以此来捕捉局部上下文信息,导致注意力的可达性有限。
- 最近发表
- 随机阅读
-
- SJCAM速影运动相机超值优惠,仅需271元
- 英伟达CEO黄仁勋:中国市场不可替代,将继续深耕服务
- 从第一到第三:卢伟冰亲自揭秘,小米电视战略大转向
- 竞技场射击游戏哪个好 十大必玩竞技场射击游戏盘点
- 倍思蓝牙耳机耳夹式1i ring限时特惠,到手价62.9元
- 马匹游戏推荐哪个 最热马匹游戏盘点
- 森海塞尔IE100PRO BLACK耳机京东优惠价494元
- 戴尔科技数据分层策略,现代化存储的智胜之道
- 微信朋友圈“访客记录”功能引热议
- 抽象游戏哪些人气高 2024抽象游戏推荐
- 暑期高空餐厅迎来打卡潮 游客奔赴高星酒店感受“云端观景”丨封面有数
- 【读财报】2025上半年保险公司合规透视:强监管持续
- 一加OnePlus 13T 5G手机超值优惠低至3299元
- 冰球游戏哪个最好玩 最热冰球游戏排行
- 米家空气净化器5京东优惠,原价999到手730
- 小米玄戒O1芯片争议:自主设计还是Arm定制?
- vivo S20 Pro松烟墨配色12GB+256GB天猫促销
- 现代战争游戏哪个好 人气高的现代战争游戏精选
- 经典游戏有哪些 下载量高的经典游戏排行榜
- 采矿游戏哪个好玩 下载量高的采矿游戏推荐
- 搜索
-
- 友情链接
-