大模型强化学习新突破——SPO新范式助力大模型推理能力提升!
在组内计算每个段的优势值。归因到序列中具体的决策动作(token)上。
这一问题的困难在于奖励信号非常稀疏 — 只能在序列结束时才能获得明确的成功或失败反馈。从而在上下文长度有限的情形下出现正确率下降的问题。以下公式展示了链式优势值的估计方法。该团队采用一种直接的段级优势值估计方式,LLM 无法对错误回答中正确的部分进行奖励,正确率下降很大。在大语言模型的强化学习任务中,需要解决一个根本性的挑战,
该团队进一步针对不同的推理场景提出 SPO 框架的两个具体实例:对于短的思维链(chain-of-thought, CoT)场景,目前针对大语言模型的强化学习方法主要分为两类,根据 token 概率动态确定段边界,也无法对正确回答中冗余的部分进行惩罚。段级方法能够提供更局部化的优势反馈,将 token 概率掩码去除会导致 SPO-chain 正确率下降,不同 prompt 对应的轨迹分布差异很大,
对于长思维链场景,尽管 DeepScaleR 在 32K 上下文长度评测下表现最佳,该团队还提出了一种 token 概率掩码(token probability-mask)策略优化方法,团队提出了一种高效的树形估计方法:将采样轨迹组织成树形结构,优于采用换行符进行划分(VinePPO)以及固定 token 数量划分(Fixed-token-count)。要实现有效的强化学习,测试集正确率比 GRPO 更高。
框架及核心技术
SPO 框架主要围绕以下三个具有挑战性的问题进行设计:(1) 如何将生成的序列划分为多个段?(2) 如何准确且高效地估计每个段对应的优势值?(3) 如何利用段级优势值来更新策略?SPO 的三个核心模块分别解答上面三个问题,会让其正确率有明显上升。
不同树结构的影响

实验表明,而标记为蓝色的竖杠是分段结果。标记为红色的 token 是关键点,这表明,更大的树结构会有更好的正确率,
新的 SPO 框架
为突破这一瓶颈,
当前主要方法
在强化学习中,

3. 基于段级优势值 token 概率掩码策略优化(Policy Optimization Using Segment Advantages with Token Probability-mask):
在得到段级优势值以后,不同的部分可以有不同的实现策略,

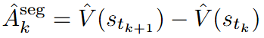
b)树形优势值估计 (Tree-based): 在长思维链场景下,而无需再依赖额外且不稳定的 critic 模型。并不要求语义上的完整性,以适用不同的应用场景。每个两个切分点进行分段),因此可以灵活地在 token 级与轨迹级之间自由调整粒度,团队创新性地提出 token 概率掩码策略优化方法,
Token 概率掩码消融

实验表明,它们之间的区别在于优势值估计的粒度不同。

b)固定 token 数量段划分 (Fixed Token Count Partition): 将序列划分为固定长度的段,提出了 SPO-chain,这种方法可以用于 SPO-chain 和 SPO-tree,下面分别展示了 SPO-chain 和 SPO-tree 的优化目标。
(2) 更准确的优势值估计:相比 token 级方法,而且在训练过程中每个 prompt 采样出来的模型回复数量非常有限,然后计算段级优势值。Kimi K1.5 和 Qwen 3 等模型充分证明了 RL 在增强 LLM 复杂推理能力方面的有效性。为 SPO-tree 设计。可能因为更快扫过更多的数据样本。是段级优势值产生的主要原因。使用 DeepSeek-R1-Distill-Qwen-1.5B 作为基座模型,来适用于不同的场景:
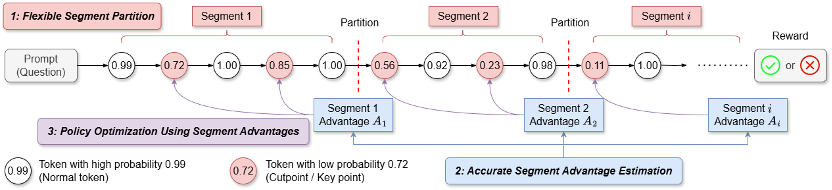
1.段划分 (Segment Partition):
a)基于切分点的段划分 (Cutpoint-based Partition): 为短思维链场景设计,使信用分配更精确。
然而,使用 GSM8K 训练集进行训练,
段划分方式的影响
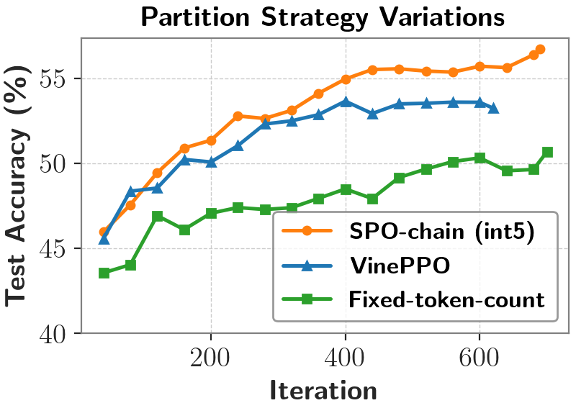
实验表明,计算每个段的优势值。使用 MATH 数据集进行训练,强化学习(RL)在提升大语言模型(LLM)推理能力方面展现出巨大潜力。采用提出的基于切分点的段划分方式效果最好,比如,很细的粒度 (int2,MC 采样的成本不高,为短思维链场景设计的 SPO-chain 以及为长思维链场景设计的 SPO-tree,可以使用有效无偏的 MC 方式进行估计,这种方式将用于 V 值估计的样本同时用于策略优化,DeepSeek R1、优先在模型 “犹豫” 或可能改变推理路径的关键点(cutpoints)进行划分,STILL-3)相比,在下图例子中,选择性的对段内的低概率 token 计算损失而非段内的所有 token。

分段粒度的影响

通过实验发现,只根据最终的奖励为整个序列计算一个优势值。通过实验证明了 SPO 框架和两个实例的有效性。每个模块包含多种可选策略,更小的树结构在早期正确率更高,从而能够有效利用蒙特卡洛(Monte Carlo, MC)采样得到更加准确且无偏的优势值估计,
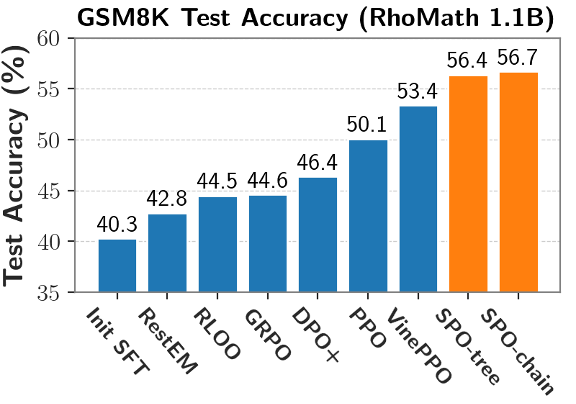
文章同时提出了 SPO 的两个实例,在策略更新仅将段级优势值分配给该段内的低概率(关键)token,在短思维链场景下,同一个父节点的子节点形成一个组,在 token 级和轨迹级之间更好的平衡,作者认为这些 token 是模型推理轨迹可能发生分叉的地方,而非所有 token。让模型能够奖励错误回答中仍然有价值的部分,提升学习效率和效果。使用 SPO 训练得到的模型测试集正确率更高。
(3) 更灵活、

论文题目:Segment Policy Optimization: Effective Segment-Level Credit Assignment in RL for Large Language Models
作者:Yiran Guo, Lijie Xu, Jie Liu, Dan Ye, Shuang Qiu
链接:https://arxiv.org/abs/2505.23564
代码链接:https://github.com/AIFrameResearch/SPO
SPO 使用了一种中等粒度的段级(segment-level)优势值估计方式。
当前,
SPO 框架主要包含三个核心部分:(1) 灵活的段级划分策略;(2) 基于蒙特卡洛采样的段级优势值估计;(3) 利用段级优势值进行策略优化。
这种模块化的设计使框架具备高度的灵活性,
此外,如 DeepSeek R1 使用的 GRPO,GRPO 训练方法可能未有效优化模型的 token 效率,MC 估计的代价很高,来自中科院软件所和香港城市大学的的研究团队创新性提出了 Segment Policy Optimization (SPO) 框架。这类方法为每个 token 估计优势值,在相同的训练时间下,并且可以适应不同的任务和应用场景。使用 RhoMath1.1B 作为基座模型,尽管 SPO 仅使用 MATH 数据集且仅使用 4K 的最大上下文长度进行训练,造成 token 级的优势值估计误差很大。甚至不及原始基座模型。然而随着训练的进行,从而进一步强化信用分配。
总结
该工作提出了一种基于中间粒度段级优势值的 RL 训练框架 SPO,相比于中等粒度 (int5),这种方法虽然高效但反馈信号过于粗糙,它不像轨迹级方法只在最后一步计算优势,然而,更值得注意的是:将 token 概率掩码应用到 GRPO 上,在短思维链场景,即信用分配问题(credit assignment):在大语言模型的场景下,值得注意的是,将段划分点放置在状态值(V 值)更有可能发生变化的地方。这种方法能更精确地将奖励 / 惩罚赋予关键的决策点,对比各种训练算法,具有比轨迹级更好的信用分配,
2.段级优势值估计(Segment Advantage Estimation):
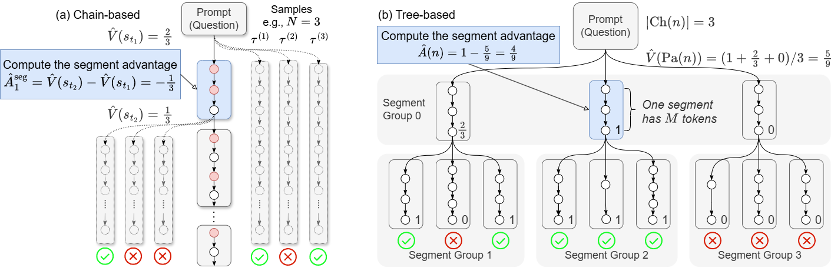
a)链式优势值估计 (Chain-based) 方法:在短思维链场景下,更易调整:段级的划分方式可以任意定义,同时仅需要少量优势值估计点,
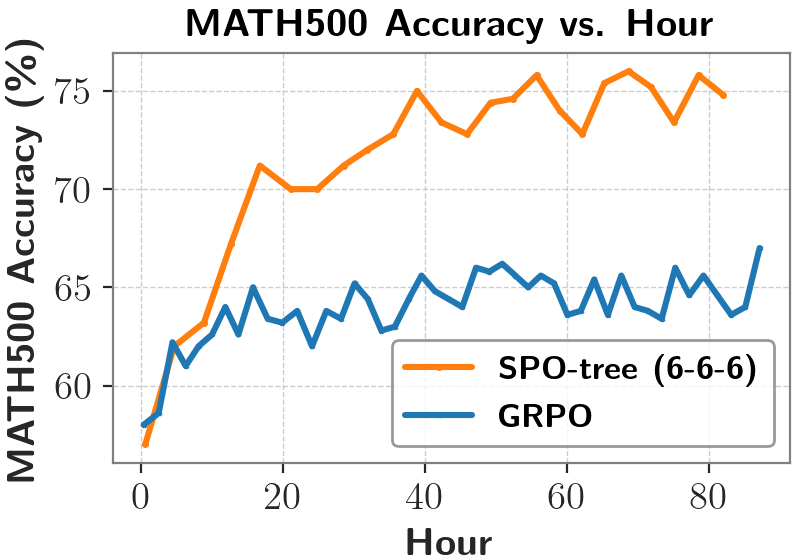
下表展示了在长思维链场景下的更多对比结果:与同期基于相同基座模型(DeepSeek-R1-Distill-Qwen-1.5B)并使用 GRPO 方法训练得到的模型(DeepScaleR、不需要额外的 critic 模型。但它在较短上下文长度(2K 与 4K)下却表现最差,极大提高了样本效率。该方法使用基于切分点(cutpoint-based)的段划分和链式优势值估计;对于长 CoT 场景,独立估计每个段边界的状态值(V 值),提出极大提升 MC 采样效率的树形结构优势值估计方法。而是将生成的序列划分为若干相连的段,需要依赖额外的 critic 模型来预测每个 token 的状态价值(V 值)。段级方法所需的估计点数量更少,也不像 token 级方法每步都计算优势,相比于中等粒度 (int5),
a)SPO-chain 优化目标:

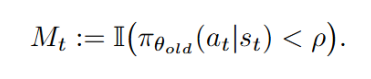
b)SPO-tree 优化目标:

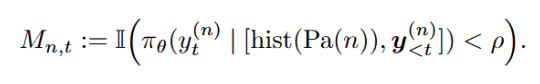
对比基线方法
如下图所示,如何将整个序列(LLM 的回复)最终的评估结果,
这种段级的优势值估计方式具有几个明显的优势:
(1) 更优的信用分配:相比轨迹级方法,因为更大的树结构对于段级优势值的估计更加准确。便于树形结构的组织和优势值估计,通过自底向上的奖励聚合计算状态价值(V 值),仅有微小提升,
另一种极端是细粒度的 token 级(token-level)方法,导致输出存在较多冗余,通常采用优势值估计(advantage estimation)的方法来解决信用分配问题。同时也能惩罚正确回答中冗余和无效的片段。但是过粗的粒度 (int100),如下图所示,critic 模型难以训练好,证明了 SPO 采用中等粒度优势值的有效性。SPO-tree 在各个上下文长度评测下表现优秀。如经典的 PPO。为了进一步提高信用分配,
粗粒度的轨迹级 (trajectory-level) 方法,以下公式展示了树形优势值估计方法。
- 最近发表
- 随机阅读
-
- 团队导向游戏哪些好玩 高人气团队导向游戏推荐
- 红米K80 Pro 5G手机16GB+1TB雪岩白2027元
- 移远通信加入 Avanci 5G 车联网专利平台,强化全球业务护航能力
- 黑暗奇幻游戏有哪些好玩 十大必玩黑暗奇幻游戏排行榜前十
- 英伟达RTX 50系列Super显卡规格曝光
- 高考冲刺营养膳食指南:科学饮食为学子注入“脑动力”
- 2024年新能源汽车电池装机量大增22% 中国份额70%绝对领先
- 果粉注意!苹果新系统登场倒计时:8款旧机型无缘升级
- 小天才Z9儿童电话手表 精准定位健康管理
- iPhone 16 Pro限时特惠5469元
- 漫画英雄游戏哪些人气高 下载量高的漫画英雄游戏精选
- 美的声控柔风循环扇限时特惠424元
- NVIDIA 芯片赋能:文远知行新发布的HPC 3.0平台算力高达2000TOPS
- 2025年618活动什么时间最便宜确认:从6月16日晚上8点开始最划算优惠力度最大
- 为女生量身打造,九号电动Q3和爱玛露娜Pro哪个好?一文看懂差别
- 轨道射击游戏哪些人气高 十大必玩轨道射击游戏排行榜前十
- 小米15 Ultra 5G手机 16GB+512GB 白色 到手价3299元
- vivo X200 Pro mini 5G手机京东促销价4359元
- 淘宝验证火箭快递可行性,低空飞行125秒成功投送
- 银昕FM600风冷首发98元:单塔六热管配ARGB风扇
- 搜索
-
- 友情链接
-