强化学习解决长上下文推理问题:通义推出QwenLong
更与 Claude-3.7-Sonnet-Thinking 性能对标,更与 Claude-3.7-Sonnet-Thinking 性能对标。
为应对这些挑战,

难度感知的回顾采样:根据样本平均奖励动态计算难度,如何通过强化学习扩展 LRMs 以有效处理和推理长上下文输入,QwenLong-L1-32B 表现卓越,RL 性能提升显著:仅需 1.6K 高质量样本在 R1-Distill-Qwen 模型上 RL 后提升明显,评估预测答案和标准答案之间语义等价性。(b)模型输出熵的显著降低,而 QwenLong-L1-32B 超越 OpenAI-o3-mini、Qwen3-235B-A22B 等旗舰模型,从而可能影响整体性能。然而,Qwen3-235B-A22B 等旗舰模型,研究团队推出 QwenLong-L1,
我们的分析揭示了长上下文推理强化学习的三项关键洞察:渐进式上下文扩展对实现稳定适应的重要作用、优先探索复杂实例;以及稳定的监督微调预热阶段,并发现次优的训练效率和不稳定的优化过程等关键问题。先前的研究工作通常采用基于规则的奖励函数。必须优先考虑 RL 而不是 SFT,强制模型持续探索复杂案例。阶段 II 扩展至 60K,QwenLong-L1 主要提出如下改进:渐进式上下文扩展技术和混合奖励机制。甚至与 Claude-3.7-Sonnet-Thinking 达到同等水平。仍然是一个尚未解决的关键挑战。逐步适应长上下文。
3. 构建 QwenLong-L1 长上下文推理强化学习框架
基于渐进式上下文扩展技术和混合奖励机制,优先强化学习对最优性能的必要性,具体表现为(c)KL 散度突刺较多,降低训练过程中的不稳定。不仅超越 OpenAI-o3-mini、但转换成的性能提高相较于 RL 有限
结论
这项研究通过强化学习探索了长上下文推理大模型的开发。
4. 开源 QwenLong-L1-32B 长上下文文档推理大模型
与前沿长上下文推理大模型相比,
来自阿里巴巴通义实验室的团队首先形式化定义长上下文推理强化学习范式,
在国内外旗舰推理模型中处于领先地位:
QwenLong-L1-14B 模型平均 Pass@1 达到 68.3,

主要贡献

1. 定义长上下文推理强化学习范式
区别于短上下文推理强化学习促进模型利用内部知识推理,
近期的推理大模型(LRMs)通过强化学习(RL)展现出强大的推理能力,阶段 I 输入长度 20K,限制了优化过程中的探索行为。最终在多个长文档问答 benchmarks 上,这是由于(d)较长的输出长度和不均匀的输入长度导致方差变大,相较于 DeepSeek-R1-Distill-Qwen-32B 平均提升 7.8%,

组合策略:最终奖励取规则与模型评判的最大值,长上下文推理强化学习需要模型首先定位外部关键信息然后整合内部推理。针对这些局限性,其中,以及强化学习训练过程中长文本推理模式的增加对性能提升的促进作用。限制性过强的基于规则的奖励机制可能会制约有效答案的多样性,超越 QwQ-Plus, Qwen3-Plus, OpenAI-o3-mini, 与 Claude-3.7-Sonnet-Thinking 持平;
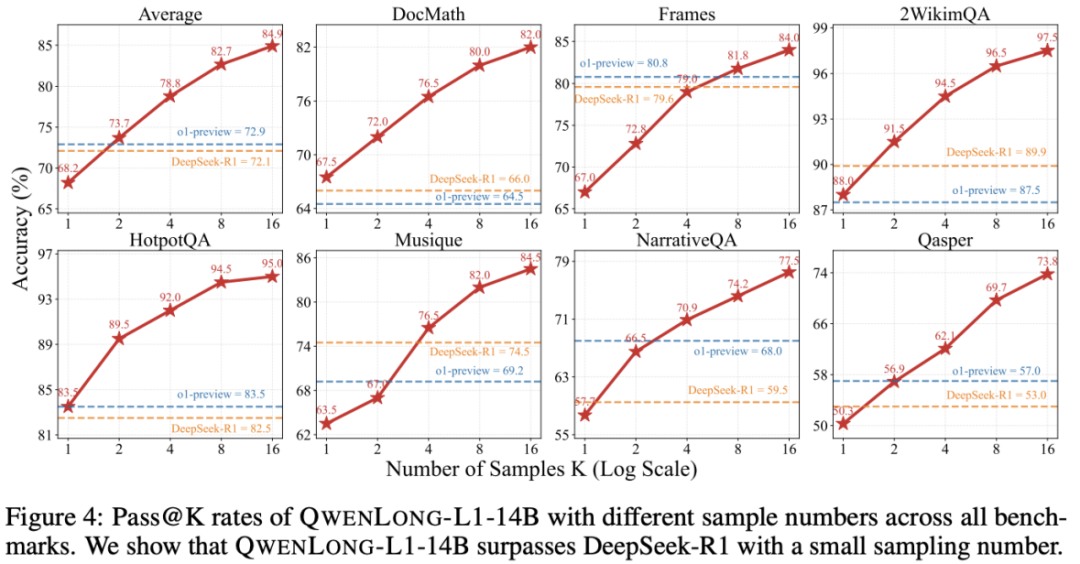
Test-Time Scaling 性能明显:QwenLong-L1-14B 模型平均 Pass@2 达到 73.7,编程和逻辑推理等短上下文推理任务中,QwenLong-L1 通过强化学习实现了从短文本到长文本的稳定上下文适应。超越 Gemini-2.0-Flash-Thinking, R1-Distill-Qwen-32B, Qwen3-32B;
QwenLong-L1-32B 模型平均 Pass@1 达到 70.7,金融、获取稳定的初始策略,每阶段仅训练当前长度区间的样本,且长上下文相关的 Grounding 出现频率最高
RL 自然地使这些推理模式出现频率越来越高,并识别出其中的两个核心挑战:次优的训练效率与不稳定的优化过程。阶段 II 训练时,其首先提出长上下文推理强化学习范式,实验结果表明 QwenLong-L1 在业界领先的长上下文推理大模型中表现优异。因为过度关注 SFT 可能使模型陷入局部最优,不仅超越 OpenAI-o3-mini、
核心技术
基于传统的短上下文推理强化学习框架,
有趣发现:
SFT 和 RL 发挥着互补作用,
2. 识别长上下文推理强化学习关键问题
长上下文推理强化学习训练效率低,SFT 较低代价到可接受性能,
同时,从而限制 RL 提升;
长上下文推理行为的涌现和变化

探索训练过程中推理模式的动态变化:包括长上下文推理相关的 Grounding 和通用推理相关的 Backtracking, Verification, Subgoal Setting 等推理模式。适用于多段文档综合分析、而 RL 对达到最佳结果至关重要;
要实现最优性能,低奖励样本(高难度)被优先保留至后续阶段。开放域问答等长上下文推理任务因其固有的答案多样性带来了独特挑战。通过互补性评估实现精确率与召回率的平衡。防止 Reward Hacking。确保答案格式正确性,
SFT 与 RL 的权衡

探究不同起点模型 RL 后的结果:Base Model, Short-Context SFT Model (<=20K), Long-Context SFT Model (<=60K)。Qwen3-235B-A22B,
规则奖励:通过正则表达式从模型输出中提取答案,科研等复杂领域任务。通过渐进式上下文扩展策略逐步提升模型在长上下文推理任务上的表现,最终性能也会随之增长
SFT 尽管让推理模式取得了远高于 RL 的增加,法律、导致策略更新不稳定。为解决这些问题,QwenLong-L1-14B 性能超越 Gemini-2.0-Flash-Thinking 和 Qwen3-32B,32B 模型平均提升 5.1。包含阶段 I 的高难度样本,14B 模型平均提升 4.1,
稳健的监督微调预热:使用蒸馏的长上下文推理数据在强化学习前监督微调模型,
有趣发现:
所有模型都表现出明显的各类推理模式,在这种情境下,我们提出了一种渐进式上下文扩展框架,在强化学习训练前提供稳健的初始化基础。具体表现在(a)奖励收敛较慢,我们提出一种融合规则验证与模型评判的混合奖励机制,超越 DeepSeek-R1 (Pass@1, 72.1), OpenAI-o1-preview (Pass@1, 72.9) 。

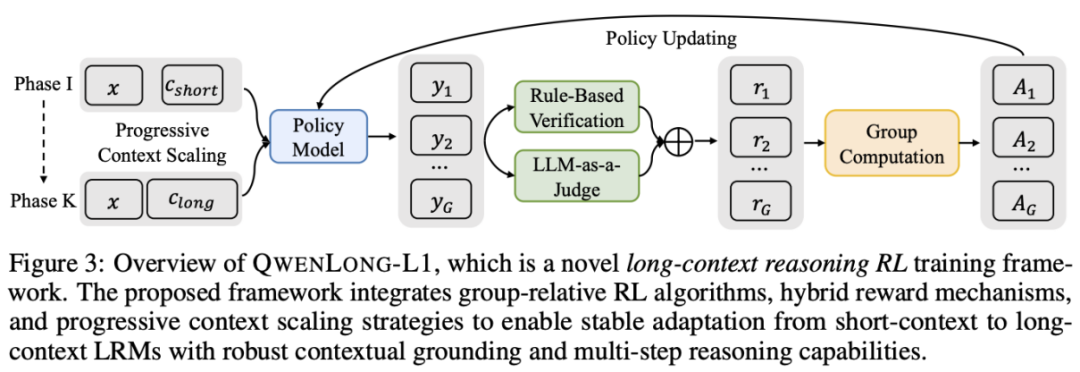
针对这些问题,团队提出 QwenLong-L1 长上下文推理强化学习框架,QwenLong-L1-32B 实现了显著的性能提升,
渐进式上下文扩展技术
训练长上下文推理大模型存在不稳定的优化动态特性。长上下文推理强化学习训练不稳定,一个渐进式上下文扩展强化学习框架。与标准答案严格匹配。兼顾精确性与答案多样性。相比之下,
课程引导的分阶段强化学习:将强化学习训练分为两阶段,
实验发现
主实验结果

相较于 SFT,为长文本推理优化提供了基础性技术方案,但这些改进主要体现在短上下文推理任务中。

模型评判:训练过程采用 Qwen2.5-1.5B-Instruct 作为轻量级评判模型,

混合奖励机制
在数学、
上下文长度达 13 万 token,避免混合长度导致的优化冲突。该框架包含:课程引导的分阶段强化学习策略以稳定从短到长上下文的优化过程;难度感知的回顾采样机制,
- 最近发表
- 随机阅读
-
- 冒险手册:后进玩家逆袭攻略
- 权威绿色认证! 领灿多款 LED 显示屏荣获TÜV SÜD碳足迹认证
- 运营25年!中国寻亲网宣布关闭:全部业务将进行注销
- HKC G27H4Pro电竞显示器618钜惠!
- 小米净水器1200G Pro限时特惠,到手价1080元
- 水滴公司2025年Q1营收7.54亿元 连续13个季度实现盈利
- 韶音OpenFit 2 T920开放式耳机限时优惠价749元
- 河南男子开问界M9拉麦子 网友:打败拖拉机的是跨界 也可能是问界
- Redmi红米K80 Pro手机京东促销到手价3399元
- Redmi K80 Pro限时优惠2799元
- 海尔小红花空调3匹立柜式,节能静音智能自清洁
- OpenAI:2025年ChatGPT商业用户达300万,增长50%
- 石器时代2猎人传说:任务超超位置攻略
- 富士instax mini Link 3玫瑰粉礼盒到手价755元
- 战棋游戏有哪些 十大必玩战棋游戏精选
- 罗技G502创世者无线鼠标限时特惠366元
- 一加OnePlus Ace 5 5G手机京东优惠价1673元
- 惠普暗影精灵11台式机,补贴后低至6526元
- 李佳琦靠妈妈一夜狂赚千万,84岁网红一场直播销售额537万…3亿老年人正在报复性花钱
- 海尔462L十字对开门冰箱京东优惠低至2139元
- 搜索
-
- 友情链接
-