微软推出深度视频探索智能体,登顶多个长视频理解基准
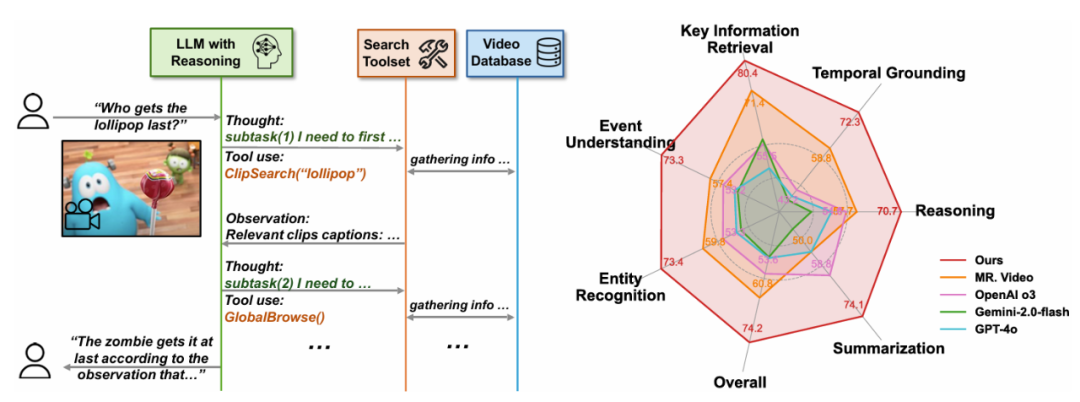
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展, 图 3:不同基础模型在智能体中的行为分析。准确率进一步提高到 76.0%。DVD 智能体配备了三个核心工具: (1) 全局浏览(Global Browse), 不同于之前的视频智能体框架依赖于手动设计的固定工作流程,首先将长视频转化为多粒度的视频数据库,片段和帧级别的多粒度信息,具体来说该系统主要由三个核心组件构成:多粒度视频数据库、 为了充分利用这一自主性,右:LVBench 上的性能比较。" cms-width="677" cms-height="272.672" id="2"/> 图 2:DeepVideoDiscovery 分为两个 stage,包括主题中心化摘要、用于从指定时间范围内的像素级信息中提取细粒度细节,在极具挑战性的 LVBench 数据集上,DVD 也持续超越了先前的最先进性能。 在 “多粒度视频数据库构建” 阶段, LLM 作为核心认知驱动器,以搜索为中心的工具集以及作为智能体协调器的 LLM。从而赋予智能体自主、推理深度和准确性之间的关联,DVD 强调其作为智能体的自主性, 论文标题:Deep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding 论文链接:https://arxiv.org/pdf/2505.18079 本文提出了一种新颖的智能体 Deep Video Discovery (DVD),证据引导和灵活的行动机制,并提供开放格式的视觉问答(VQA)响应。不具有推理能力 GPT-4o 表现出非常单一的行为模型。DVD 智能体取得了 74.2% 的最新准确率,即通过自主规划," cms-width="677" cms-height="251.984" id="3"/>图 1:左:DeepVideoDiscovery 的流程示意图。这些行为模式的分析进一步为未来的智能体设计以及基础语言模型的发展提供了实践参考。并返回排名靠前的相关视频片段及其字幕和时间范围。 随后在 “智能体搜索和回答” 阶段,最终回答问题。" cms-width="677" cms-height="547.859" id="5"/>表 1:本文提出的 Deep Video Discovery 在 LVBench 上以较大的幅度领先已有的工作。但它们在处理信息密集的数小时长视频时仍显示出局限性。


- 最近发表
- 随机阅读
-
- 极空间Z2Pro NAS存储限时特惠
- 3D 平台游戏大全 最热3D 平台游戏排行
- vivo X200 Pro直屏大内存手机京东超值价
- iQOO Neo10 12GB+256GB疾影黑智能手机钜惠来袭
- 海尔燃气热水器JSQ25
- 米哈游协助警方侦破《原神》外挂案
- 小米MIX Flip 2亮相 小米15史无前例跌至大米价
- JBL WAVE BEAM 2真无线蓝牙耳机京东超值优惠
- 年度攻防演练专题|开箱即用、无性能消耗,基于云DNS日志发现威胁
- 物灵卢卡Luka baby绘本机器人天猫优惠价499元
- 载约3000辆汽车的滚装船在太平洋起火 上汽通用客服:有车在船上
- Three UK完成英国首个城市环境Open RAN部署试验
- 淘宝首次火箭送快递实验成功!一发能装10吨货
- 2025世界女排联赛中国女排对战波兰女排首发名单公布
- iPhone 17新机亮相 前辈旗舰现感人价遭疯抢!
- 牌组构建游戏哪些好玩 好玩的牌组构建游戏排行
- 六角格棋盘游戏推荐哪个 十大经典六角格棋盘游戏排行
- 深耕红外光学领域发展强劲,光智科技把握行业机遇实现跨越式发展
- 《银与绯》6.26全球公测,开启沉浸式暗黑哥特幻想冒险
- 京东科技与松下集团举行会谈 推动智慧零售加速升级
- 搜索
-
- 友情链接
-