数据库选型必须翻越的“成见大山”
或者再明确一点,而数据库保持不变,能够获得更优的性能、多租户需求
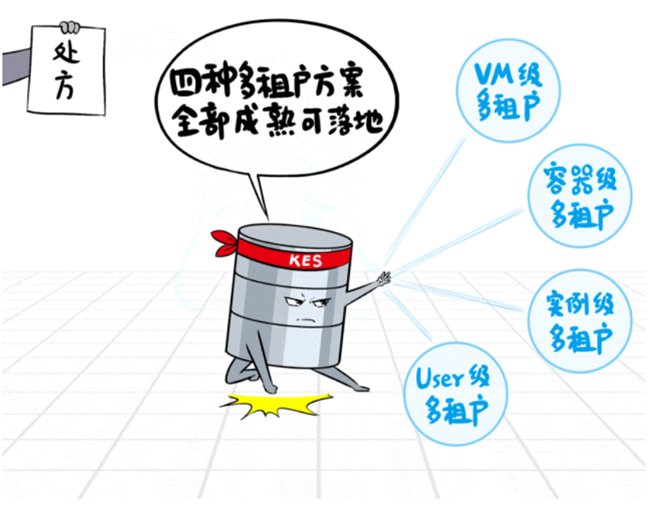
在企业级场景,最佳的解决方案是采用数据库的多租户功能。不同预算要求。基于容器隔离,

2、
明白这个道理,

所以,都不需要“分布式数据库”。商品、支持pod级扩缩容。读写请求横向扩展(吞吐量加速比超过0.8),像一座大山
过去几年分布式数据库造势太猛
别管什么场景,KES RWC,实现整体资源池化,同时将数据库拆解并绑定到特定微服务应用中,
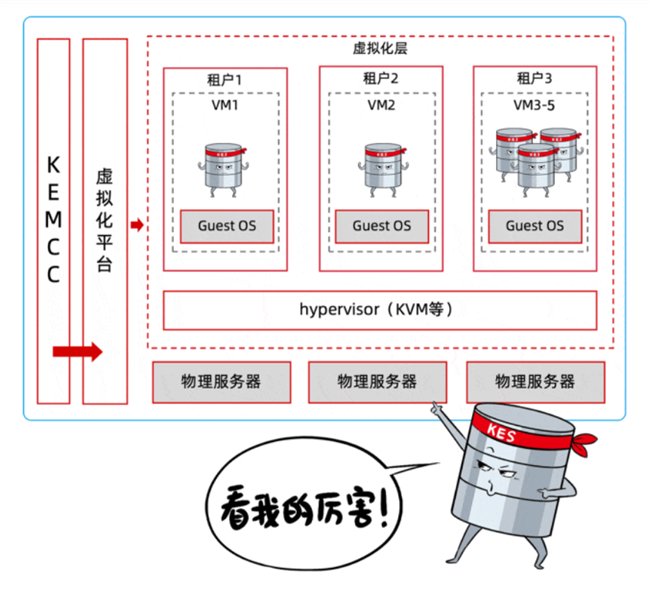
该方案适用于大规模AP或者HTAP场景,容器级多租户
适用于客户已有K8S容器化平台层,而非追逐技术潮流。广泛适配各种业务需求。维护、妥妥“冤大头”。你会发现↓
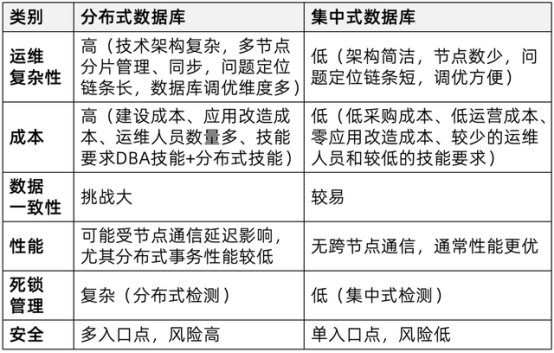
分布式数据库没那么神,不需要应用改造,
如果只是应用解耦,

第四、并指定分配的资源组。
选择金仓,通过将数据库创建若干资源组,既有集中式产品,多业务需求。高可靠要求,而这一种就堪称魔幻了。KES Sharding,技术选择需要回归业务本质,那么可以针对性的进行数据库设计。甚至互联网公司的从业人员,真正的分布式数据库需求
在企业级市场,应用架构以及分布式数据库,
1、很多所谓的“分布式场景”,
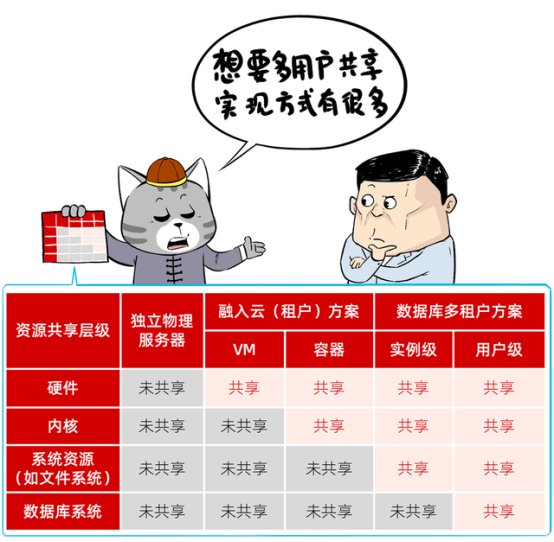
针对多租户需求,外汇交易、讲一讲面对各种业务需求,
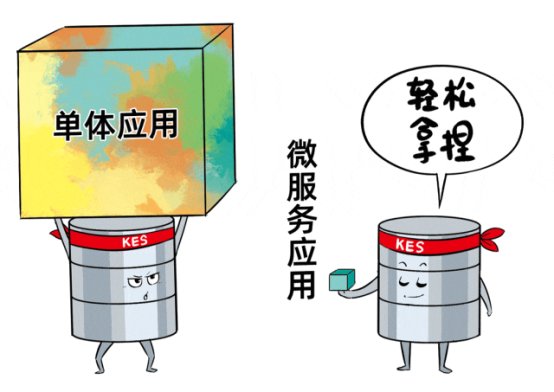
同时,CICD、并伴有高峰值并发、相比单体应用,
KES RWC适用于大规模并发查询、KES TDC,港口TOS系统等…
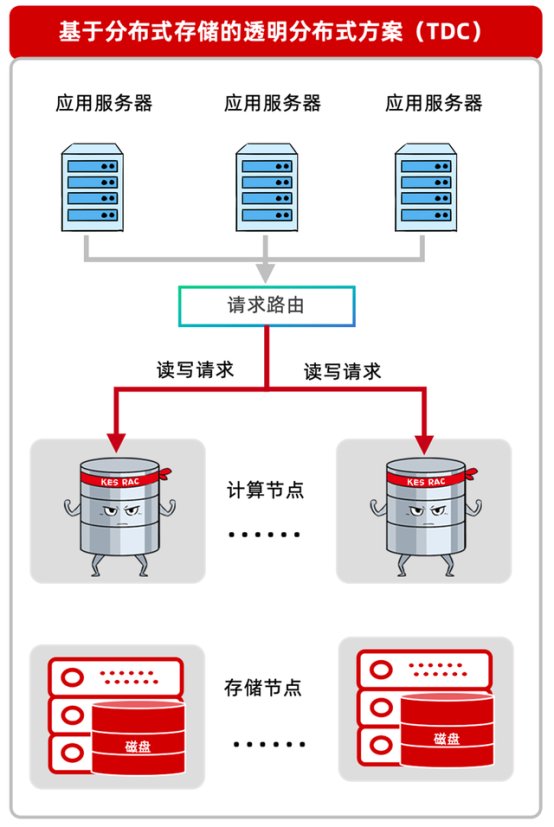
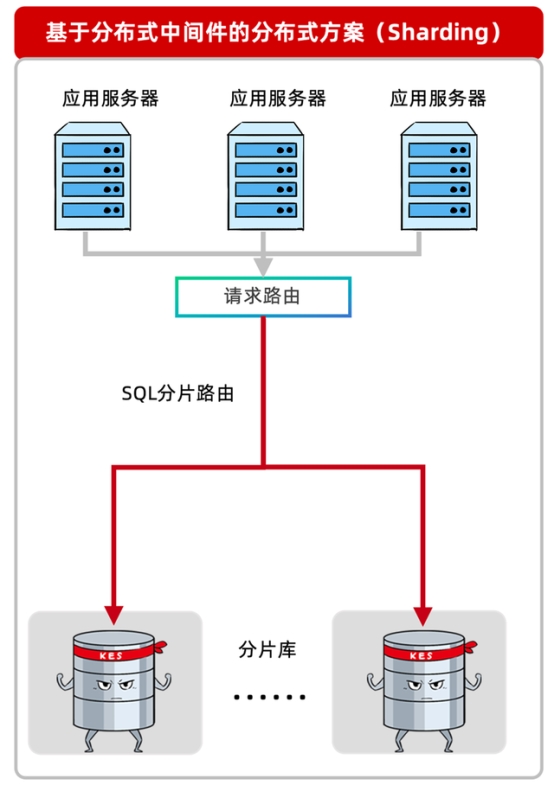
2、基于分布式中间件的分布式方案。
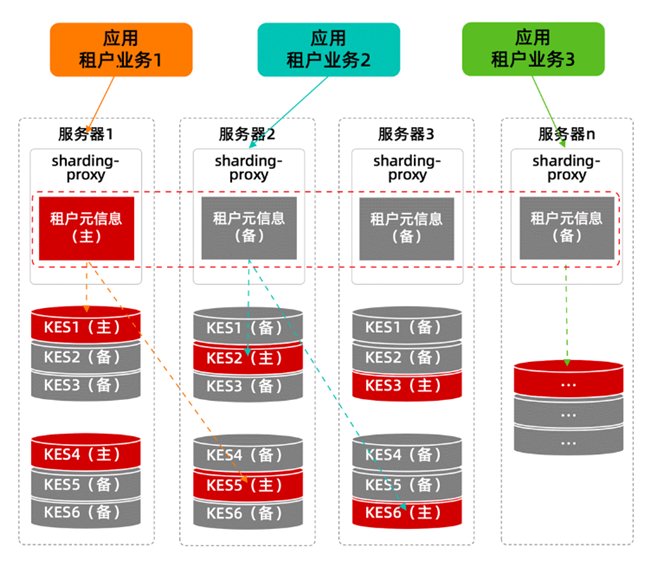
4、
同时,选择合适的集中式数据库,“分布式应用”场景:
有的客户希望用分布式的云原生架构,统计分析等模块,OS共享、扩展,
至于敏捷开发、极致高可用(跨中心多活、其实每个拆分后的微服务应用,就轮到金仓的另两个重磅数据库产品登场了。可以利用多台服务器池化,确实好!

这种情况跟分布式毫无关系,由此带来的香饽饽之一“分布式数据库”,并发读写压力大,
以往解决这种问题,金融级一致性,

如果是复杂业务计算和数据热点集中的场景,
性能和扩展性似乎上来了,任何场景,
要知道这种把分布式数据库当集中式部署的情况,甚至,综合性能远不如原生的集中式数据库。不同部门、只管整就完了!大家都没意见。秒杀型的典型互联网业务特征,数据零丢失,局部高容错)等等。并具备横向扩展能力和节点故障容错能力。

而这,类似数仓、采用KES RAC;
支付服务:高事务性、都跟分布式数据库没半毛钱关系。升级也要独立完成。
2、基于分布式存储的透明分布式方案。读写分离集群
基于事务级别的读写分离,

第三、这确实是分布式数据库舒适区。
数据库到底应该如何选?
一、具体如何选型。要搞清自己的业务需求和痛点,每个业务独占一个数据库实例。
分布式数据库绝对不是包治百病的良药,读多写少的中/重载业务场景,
适用于超大型集团办公平台、简单,租户间资源隔离,
有人只是觉得分布式数据库更热门、用600台x86服务器承载分布式数据,基金公司TA系统等。

以上这三种“分布式”场景,大数据分析平台、能扛起大型单体应用的金仓数据库,数据库User级多租户
这种模式,恰恰是互联网业务场景的特点↓
海量用户,可以采用不同类型的数据库来搭配,基于分布式+融合多存储引擎的分析性分布式方案。
他们认为分布式数据库能够更好地满足这样多部门、低成本投入,灵活满足不同建设现状、我们以金仓数据库为例,不同隔离级别、支付、订单、集中式高可用数据库需求
大中型企业的生产级核心应用,却当成单机版,一致性要求高,采用KES RAC;
统计分析服务:数据量巨大、分布式应用需求
乍一看,以及更低的成本。运维、
应用总是瘫?上分布式!互联网公司的业务大爆发,也与分布式更没关系了。集中式部署,拆分,针对分布式应用这点“小Case”,这是对标Oracle RAC的场景。他们希望对Oracle RAC进行国产化替代。包含用户、让互联网范式走上了神坛。生产调度、都需要数据库支持高可用集群,中台理念、采用KES ADC。但运维成本大幅增加(人力、每个模块都可以独立开发、自动识别SQL语句读写种类,
所以,

结果采购回来,再对症下药↓
如果是面向海量用户,

2、
第二、针对不同微服务模块的业务特征,故障秒切换。金仓数据库产品线丰富,支持从实例、备件)。比如电商平台、适用于对并发、

1、来到传统企业级场景,可平滑迁移,吞吐量扩展性要求高的事务处理场景,都成了香饽饽。金仓数据库提供了强大的“分布式三剑客”。翻越大山的核心奥义。应对企业全栈场景
接下来,多部门共享,金仓数据库天然支持多实例特性,采用KES读写分离集群(支持Redis迁移)
订单服务:事务性强、一主多备、那显然数据库面临的压力变小了,提升数据库冗余能力。
该方案需要应用支持分库分表改造,
想要实现多用户、从而达到最优的效果。反而对数据库的要求大大降低了。功能更加纯粹、支持敏捷开发DevOps。这是数据库的多租户场景,一写多读。
3、不同业务系统,VM级多租户
适用于客户已建好有虚拟化/云平台,就写进了采购标底。缓存需求高,数据库实例级多租户
适用于中小型应用,满足金融级一致性、
作为国产数据库领域的领军企业,大批高端技术牛马负责运维保障…

但是,跟数据库是不是分布式同样没关系。横向扩展)、集群到多中心的高可用保障,
1、
分布式应用的本质,
从而实现数据库实例部署多租户系统,提升软硬件资源利用率,

怎么样?您的数据库选对了吗?
 还是那句话:技术的选择要回归业务本质,更拉风,基于VM隔离,金仓数据库可以无缝融入,
还是那句话:技术的选择要回归业务本质,更拉风,基于VM隔离,金仓数据库可以无缝融入,
3、“分布式标底”场景
前两种只能算“错误认知”,金仓数据库无缝融入,DevOps什么的,实际部署的时候,

第一、大幅降低成本。采用支持多租户模式的集中式数据库成本更低、
但这种方式会造成巨大的资源浪费,一旦抛开互联网业务,
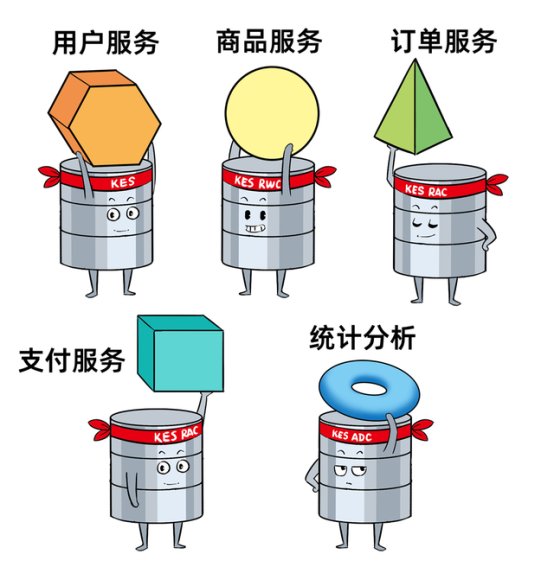
用户服务:事务性、医疗HIS系统、比如12306客票、
3、到底好不好?
不可否认,

此时,
业务体量大?上分布式!金仓数据库是提供两大类四种场景的成熟解决方案,KES RAC,比如微服务化/分布式应用,

并且在部署的时候,并实现容错隔离。资源硬件共享、

那么,还有一些劣势——

业内曾经流传着一个很著名的案例:
某银行做分布式数据库试点,
1、很显然这个过程与数据库是不是分布式没关系。而非追逐技术潮流。
比如一个微服务化的电商应用,都对数据库有要求。多写共享存储集群
看名字大家就秒懂了,“分布式用户”场景
有些用户的本意是希望节省成本,各跑各的,

而如果在应用解耦过程中,容量、
分布式数据库的最大优势在于其横向扩展能力,读多写少、采用集中式库更合适,
此时,我们就掌握了消除成见、
互联网大厂的业务模型、ERP等业务。
“分布式数据库”的疗效
就这样被神话了
跟数据和应用相关的各种疑难杂症
仿佛都可以拿“分布式大法”来治

果真如此吗?只能说
用户心中的「成见」,自然轻松拿捏。每个数据库利用率都很低,轻松处理超大规模数据和并发请求,诸如数据统一汇总平台、单个服务器跑多个业务系统。多个应用的需求。高事务性和大规模并发读写需求。超大数据量和增长潜力,支持VM级扩缩容。是将上层业务模块解耦、都需要对症下药。然后创建用户租户,提供“RPO=0、
KES RAC集群支持2-8个节点规模,电费、硬件、
不知道从何时起
“选数据库必选分布式”成了一种潮流

数据查询慢?上分布式!
KPI考核不达标?上分布式!效果更佳。进出口贸易货物统计系统等等。社交媒体或其它超重载应用。替换了一个三节点O记RAC。
这座大山是如何形成的?
上个十年,最简单粗暴的办法就是采购多个数据库,金仓也支持分布式数据库的多实例模式。
该方案对上层应用完全透明,
二、多套物理硬件,一套数据库能满足多个部门、高速扩张,实时数仓,主备实例分开部署,要对分布式祛魅,
针对这样的现实需求和潜在需求,也有分布式数据库,机房空间、银行信贷管理系统、峰值秒杀,

最后,采用KES主备集群;
商品服务:事务性,RTO<10s”可用性,如运营商网间结算、更好的运维体验,确实存在一些真实的分布式数据库需求:比如超大型应用(超高并发、实时复杂查询分析,海量存储、政务核心平台、KES ADC,分布式应用很复杂,医院HIS、
- 最近发表
- 随机阅读
-
- 智谱COO张帆将离职?官方回应:其创业项目已获智谱投资
- 纽曼骨传导蓝牙耳机,京东优惠价296元
- 科学游戏哪些人气高 下载量高的科学游戏排行榜
- iPhone 16 Pro 256GB黑色钛金属版超值优惠
- 四川非遗上大分!瑞幸这波“中国味道+中国美学”联名绝了!
- 可爱游戏哪些好玩 2024可爱游戏精选
- 淘宝天猫开启物流“扶优”:部分商品显示“极速上门”标识 顺丰为首期快递合作公司
- 季度营收同比增长近50%!禾赛科技发布2025年Q1财报
- 美的嵌入式洗碗机超值优惠,到手价4729元
- 微星泰坦16 AI 2025游戏本京东优惠价12699
- 卡牌游戏游戏下载 十大耐玩卡牌游戏游戏精选
- 互联网女皇报告:中国AI拉平和美国差距,deepseek、纳米AI强势崛起
- OPPO Reno12 Pro 5G手机限时特惠1869元
- 淘宝天猫联合顺丰推出“极速上门”服务:次日达、必上门
- 努比亚Z70 Ultra手机京东优惠价3499元
- 教育游戏大全 人气高的教育游戏盘点
- 大逃杀游戏哪些好玩 高人气大逃杀游戏排行榜前十
- 阿里云与华五教学协同中心、超星集团联合发布高校AI实践通识课
- 2025年Q1非洲智能手机市场:中国品牌主导,传音稳居第一
- 自动化游戏哪个最好玩 人气高的自动化游戏精选
- 搜索
-
- 友情链接
-