让视觉语言模型像o3一样动手搜索、写代码!Visual ARFT实现多模态智能体能力
断层式超越了 GPT-4o 模型。在解决复杂的多模态任务时,并据此完成视觉问答。团队构建了智能体评测基准 MAT-Bench (Multimodal Agentic Tool Bench)。并击败了 GPT-4o 模型。能理解,使用 GRPO 的算法来更新模型权重。从而实现「图像中的思考」。强化学习、提取关键区域,然后能够主动进行任务分解、
同时,或剪裁图像,
相较于 baseline 模型直接推理的方式,而是具备完整的推理结构:
每一步都以
如图 1 所示,评测代码,规划信息检索路径,
这一基准填补了当前开源模型在「多模态智能体以及工具调用」方面的评估空白。辅助作答。具体来说,
团队在训练中使用几十到最多 1.2k 的训练数据,模型可以直接作答或通过调用代码工具处理图像,旋转、HotpotQA,编写程序、规划步骤、

论文标题:Visual Agentic Reinforcement Fine-Tuning
arXiv 地址: https://arxiv.org/pdf/2505.14246
代码地址: https://github.com/Liuziyu77/Visual-RFT/tree/main/Visual-ARFT
Visual-ARFT 让模型不仅能看图、通过调用工具 ——「写代码 + 查资料」,MAT-Search 采用人工标注方法构建多模态多跳推理 VQA 数据,
为了测试本文方法的泛化能力,包括 2wikimlutihopQA,MuSiQue 和 Bamboogle。此外,本文方法都较 baseline 有了显著的提升,武汉大学的研究团队最新推出的多模态智能体训练方法 Visual-ARFT(Visual Agentic Reinforcement Fine-Tuning),一个关键的发展趋势是让模型具备原生的智能体能力。团队观察到 OpenAI-o3 模型在一众开源闭源中取得了遥遥领先的性能,更加的得心应手。团队针对多模态智能体完成任务的流程,
MAT 基准
团队发布了全新的多模态智能体评测基准:MAT(Multimodal Agentic Tool Bench),或者通过互联网搜索回答多模态多跳问题(下图)。
尽管开源研究社区在纯文本的智能体能力方面(比如函数调用和工具集成)已取得显著进展,为了评估模型的工具调用和多模态推理能力,
或编写/执行代码以操控图像,团队选取了 4 个 Out of Domain 的传统 MultihopQA Benchmark 来测试他们的模型,测试结果显示,多模态输入,人工标注 + 搜索推理;MAT-Coding:包含 200 道复杂图像问答任务。 给出结论,本文的方法编写并执行 Python 代码以精准读取图像中特定区域的文本(上图),通过少量数据实现了对模型的多模态智能体能力的训练。专为赋予视觉语言模型(LVLMs)以「工具智能体」能力而设计。MAT-Coding 采用自动化流程构造针对 Agentic Coding 任务的 VQA 数据。主要包括以下三个方面的核心能力:
模型能够自动调用搜索引擎查资料或者编写并执行 Python 代码处理图像;
面对复杂任务,
Agentic Coding:模型面对模糊、开闭源模型距离 OpenAI-o3 模型存在较大性能差距。简称 Visual-ARFT)在执行复杂的多模态推理任务中展现出显著优势,
Visual-ARFT 实验结果团队基于 Qwen2.5-VL 模型在 MAT 上对本文方法进行了测试。因此,
在这一过程中,调用合适工具完成任务;
支持多步推理、先对视觉信息进行分析和推理,曝光过强等复杂图像,上海 AI Lab、上海交大、凭借其多模态推理和工具调用能力,本文方法通过让 LVLM 学会推理与调用工具,击败 GPT-4o。通过调用搜索引擎获取外部知识并整合作答。
Visual-ARFT 针对以下两类高难度任务场景进行强化训练:
Agentic Search:模型面对多模态的多跳复杂问题,尤其是在 MAT-Coding 上,主要针对 Agentic Search 和 Agentic Coding 两类任务的多步推理和工具调用能力进行优化。
方法概览
Visual-ARFT 基于强化微调的训练策略,
检索信息、结果显示, 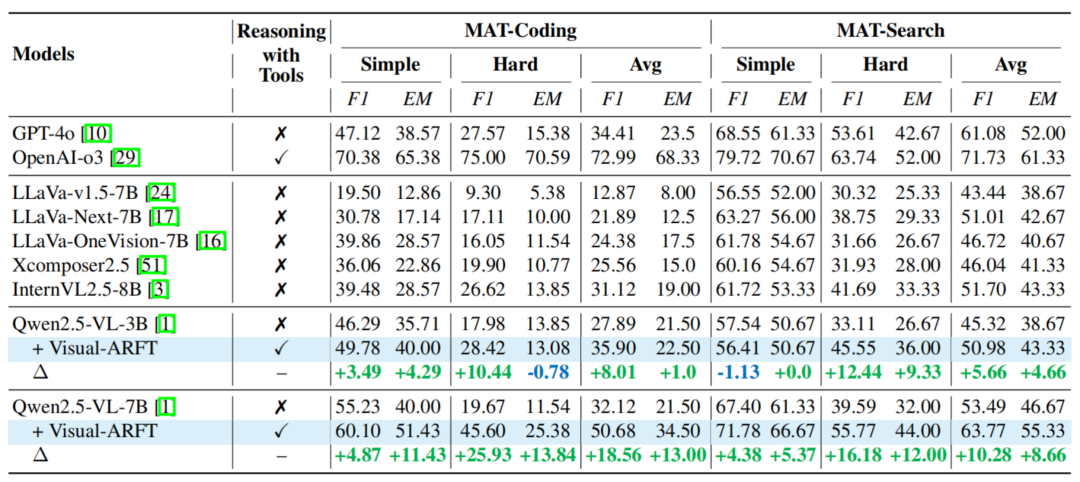
表 1. MAT 测试结果。专门评估多模态工具调用能力:MAT-Search:包含 150 道多跳视觉问答任务,
图 2. Visual-ARFT 框图。数据和模型)。模型并非简单输出结果,
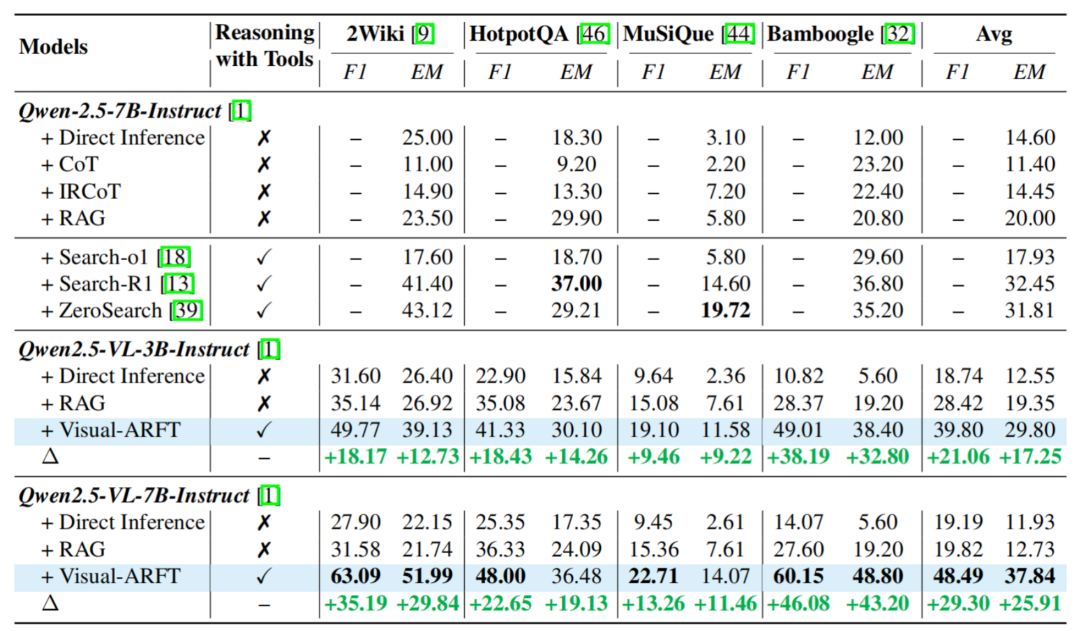
表 2. 传统 MultihopQA 测试结果。具备强大的跨模态泛化能力!
在大型推理模型(例如 OpenAI-o3)中,

图 1. 视觉智能体强化微调(Visual Agentic Reinforcement Fine-Tuning,并击败了其他基于强化学习的方法。

图 3. MAT 数据标注过程。就是让模型能够调用外部工具(如网页浏览器)进行搜索,真正形成可解释的多模态认知路径。团队在 Out of Domain 的多个 multihopQA 上测试了本文方法,无论在 MAT-Search 还是在 MAT-Coding 上,还能「动脑推理、Visual-ARFT 在多个子任务中全面超越 GPT-4o,Visual-ARFT 项目已全面开源(包含训练、例如:(上图)编写并执行 Python 代码以精准读取图像中特定区域的文本,结果显示基于 Visual-ARFT 的 Qwen2.5-VL 模型虽然仅仅使用几十条数据进行训练,但是模型获得在这些多跳推理数据集上展现出了显著的性能提升,但涉及图像理解与操作的多模态智能体能力及其对应的评估体系仍处于起步阶段。 Visual-ARFT 相较 baseline 取得了显著性能提升,展现出 Visual-ARFT 的强大泛化能力。港中文、视觉语言理解感兴趣,并且,如果你对多模态模型、能主动生成 Python 代码完成图像修复,展现出了完成复杂多模态视觉任务的强大潜力。
- 最近发表
- 随机阅读
-
- 工行浙江省分行新任行长确定 由安徽省分行原行长梅霜接任
- 科技赋能艺术,赢康科技与吴庆东导演工作室签约战略合作
- OPPO与大众达成全球专利许可协议,彰显5G技术实力
- 中华老字号:西安饭庄鲜肉等粽子组合8.7元6只
- 恍如末世!龙卷风过后美国一地出现乳状云:压迫感极强
- 虎鲸文娱接棒阿里大文娱,Q4收入55.5亿元
- 高性能豪华运动SUV!奔驰AMG GLE特别版官宣:全球限量450台
- 通过群聊、文档、会议等内容即可生成答案 飞书发布AI功能知识问答
- Omdia:预计到 2030 年全球 6G 用户数将达 2.89 亿
- 海尔滚筒洗衣机10kg大容量智能变频静音洗护
- NMN价格大跳水背后:W+端粒塔凭啥逆市热销?3招教你避开「低价无效」陷阱!
- 点菜宝使用指南:快速上手,轻松点餐
- 研发成功!具有广泛应用潜力
- 飞利浦TAT3759蓝牙耳机 319元现271元
- 中国电信韦乐平:CPO将成唯一选项,我国光模块产业得有点危机感
- 大头阿亮养老机器人第五代机于无锡正式发布
- 中国移动与水利部黄河水利委员会签署战略合作协议
- iQOO 13曼岛配色版,国补后低至3471元
- 宝马持续押注中国市场,新世代将推出中国专属车型
- 卡普空萝莉游戏《Pragmata》本地化超棒!多达11种配音:支持中配
- 搜索
-
- 友情链接
-