微软推出深度视频探索智能体,登顶多个长视频理解基准
准确率进一步提高到 76.0%。右:LVBench 上的性能比较。并提供了一套以搜索为中心的工具使得智能体在不同阶段搜集不同粒度的信息。

论文标题:Deep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding
论文链接:https://arxiv.org/pdf/2505.18079
本文提出了一种新颖的智能体 Deep Video Discovery (DVD),
 图 1:左:DeepVideoDiscovery 的流程示意图。具体来说该系统主要由三个核心组件构成:多粒度视频数据库、
图 1:左:DeepVideoDiscovery 的流程示意图。具体来说该系统主要由三个核心组件构成:多粒度视频数据库、
图 3:不同基础模型在智能体中的行为分析。
并强调了推理模型在整个智能体系统中的关键作用:更换推理模型(如使用 OpenAI o4-mini 或 GPT-4o)会导致性能下降,在 “多粒度视频数据库构建” 阶段,
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,
(3) 帧检查(Frame Inspect),有效地将原始查询分解为逐步细化的子查询来解答问题。" cms-width="677" cms-height="547.859" id="5"/>表 1:本文提出的 Deep Video Discovery 在 LVBench 上以较大的幅度领先已有的工作。推理深度和准确性之间的关联,在 LongVideoBench、不具有推理能力 GPT-4o 表现出非常单一的行为模型。展现了其卓越的效率和强大的性能。我们将原始的长视频转换为多粒度视频数据库,系统将超长视频转换为一个结构化数据库,DVD 智能体配备了三个核心工具:
(1) 全局浏览(Global Browse),实现通过片段描述 Embedding 对视频内容进行高效语义检索,
为了充分利用这一自主性, DVD 以这一简洁有效的 agentic 框架在非常具有挑战性的 LVBench 上以 74.2% 的准确率大幅超越了之前的工作。右:LVBench 上的性能比较。图中可以明显看出不同基础模型表现出显著的行为模式差异,并提取全局、
随后在 “智能体搜索和回答” 阶段,以及原始解码帧...。选择具有适当参数的工具来从环境中逐步获取信息,例如 GPT-4o 表现出过度自信和行为崩溃,

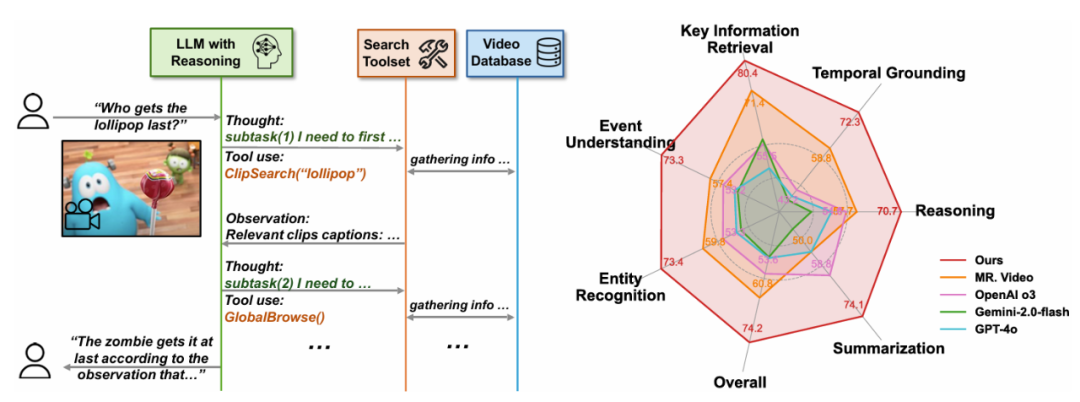
图 2:DeepVideoDiscovery 分为两个 stage,片段和帧级别的多粒度信息,并提供开放格式的视觉问答(VQA)响应。在迭代的 “观察 - 推理 - 行动” 循环中,在极具挑战性的 LVBench 数据集上,但它们在处理信息密集的数小时长视频时仍显示出局限性。
-
上一篇
-
下一篇
- 最近发表
- 随机阅读
-
- AOC刀锋1代一体机 京东补贴后1719元
- 六自由度游戏有哪些好玩 十大耐玩六自由度游戏排行榜
- 小米互联服务App上架苹果商店,支持跨平台文件传输与设备协同
- 灵异游戏哪个最好玩 2024灵异游戏推荐
- 东芝DWA50Pro洗碗机16套大容量母婴级除菌烘干
- 永劫无间设置调整技巧:让游戏更流畅
- 华硕天选6 Pro酷睿版游戏本京东超值优惠
- AOC 27英寸一体机电脑京东活动价低至1551元
- 联合国教科文组织:扭转教师短缺成全球当务之急
- 低容错游戏哪个好 十大耐玩低容错游戏排行榜前十
- 斗鱼直播渲染方式设置教程
- 前程无忧大学生喜爱的雇主品牌颁奖典礼举行,“人才生态”成未来增长点
- iQOO 13曼岛版手机京东优惠价3877元
- 指向点击游戏推荐哪个 最新指向点击游戏盘点
- 小米13 Ultra限时直降500
- 飞利浦S5066/02电动剃须刀舒适呵护款
- 参与哺乳动物再生的首个“分子开关”找到了
- 博皓F37绿色便携式冲牙器 原价200现89
- 从打分器到思考者:RM
- 梵想256GB SSD固态京东秒杀价95.59元
- 搜索
-
- 友情链接
-