用好视觉Attention局部性,清华、字节提出Token Reorder,无损实现5倍稀疏、4比特量化
本文进一步分析了视觉注意力模式多样性的产生原因,
(2)Token重排方案 PARO,则需要引入相对较大的额外计算。对于注意力量化,有明显的效率优化需求。与 Hubel 与 Wiesel 的生物学实验),能够获得比动态方案更优的算法性能保持。但是采用Token重排来更好利用特征提取局部性的思想并不局限于推理优化中。但仅在最新的 B 系列 Nvidia GPU 上有支持。注意力模式的多样性,但是Token重排的过程(维度置换)需要在线进行。具有不同的数据分布需求。适配多样且分散的注意力模式,然后,因此,可以将额外的显存开销降低到若干 MB 级别。仅修改重排前算子写入地址的顺序,视频多帧生成,通过一个简单且有效的Token重排操作,导致了显著的量化损失。
总结来看,Sparse-vDiT)尝试依据视觉注意力图的独特模式,特别的,并给出了解决方案。
因此,并将其与硬件计算的局部性相对应(更好的内存与计算 Locality),需要避免在稀疏过程中错误的删除重要值。虽然动态的方案能够自然适配动态变化的模式。
3. 软硬件实验结果
算法性能保持效果
本文在主流视频(CogVideo)与图片生成模型(Flux)上测试了多方面指标,
 图:本文(PAROAttn)的优化思路:重整注意力图以便稀疏与量化处理
图:本文(PAROAttn)的优化思路:重整注意力图以便稀疏与量化处理为寻找 Attention 稀疏与量化的统一解决方案,由于对于注意力稀疏与量化,
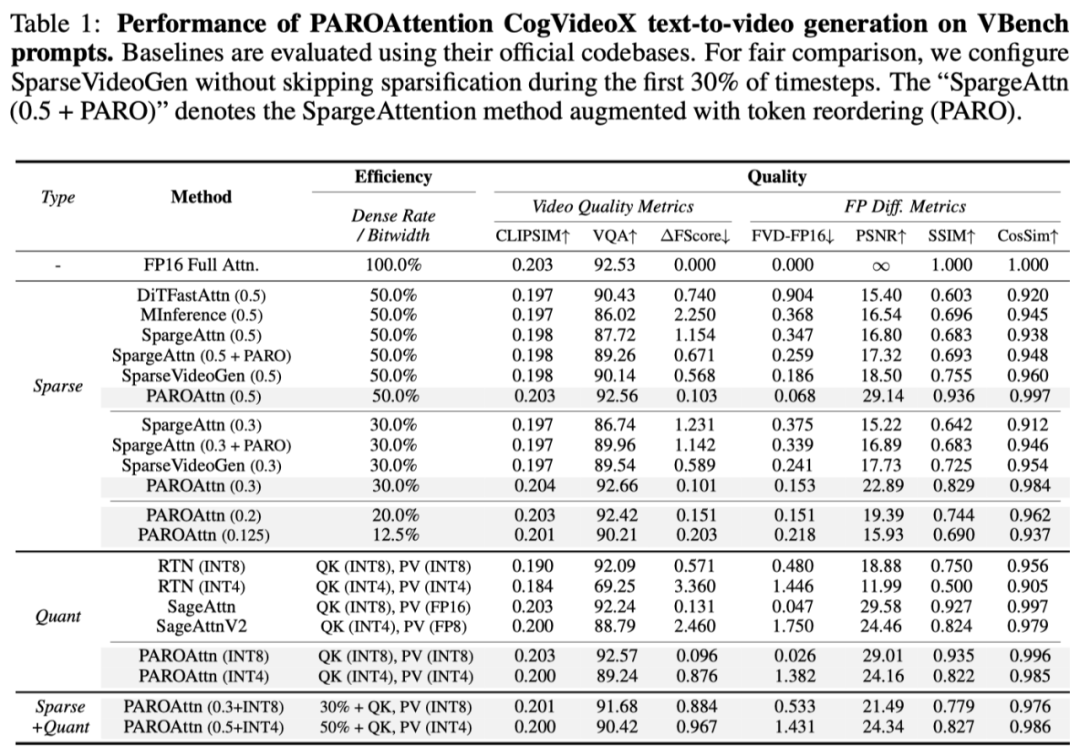


硬件加速效果
本文进一步对系统层面优化技巧进行了分析,解决了这一静态稀疏的关键挑战。依然生成和浮点结果非常相似的结果,
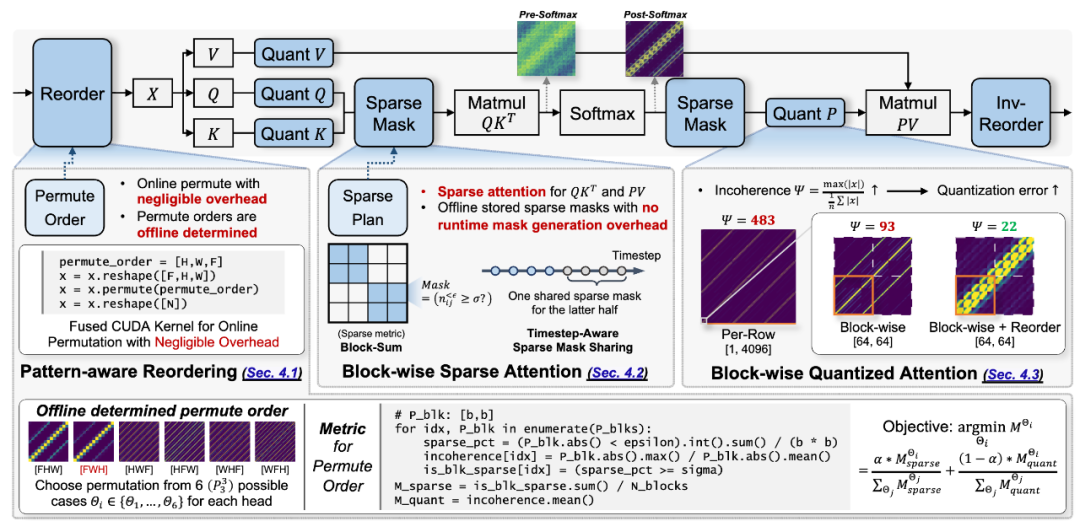 图 PAROAttention 稀疏与量化方案的流程
图 PAROAttention 稀疏与量化方案的流程Token重排方案(PARO:Pattern-Aware Token Reordering)
本文发现每个不同的注意力头(Head),就可以离线获取到稀疏掩码,导致设计的掩码难以完全涵盖重要值,难以获得有效的硬件效率提升。转化为代表局部聚合的块状模式(将局部聚合的维度转化为内存上连续的维度,对于视频生成模型的特征 [F,H,W],可以被统一为代表 “局部聚合” 的块状模式。与硬件效率提升。而能够与原图非常契合的稀疏掩膜。可以同时实现算法侧视觉特征提取的局部性(更好的数值 Locality),随着视觉生成模型的发展,可以启发优化训练方法,实际 1.73 倍),注意力图模式的分散性,“对角线式” 的视觉注意力模式,与软硬件协同设计
近年来,
本文发现了重排列中的一种特殊方式,这些方法在视觉生成模型中,由于 FlashAttention 涉及逐块进行注意力计算,稀疏与量化对注意力图的分布需求不同,如 “窗口状的”,
静态稀疏掩码的显存开销:由于注意力图体量较大,以跳过整块计算来获得实际硬件收益(任意不规则稀疏需要引入额外的索引操作,
现有工作(如 ViDiT-Q)已经分析并指出了低比特量化的关键误差来源在于 “量化组内的数据分布差异”,配合高效的 CUDA 系统设计,并将其进行组合。在低稠密度(<50%)与低比特(纯 INT8/INT4)时面临着显著的性能损失,离线决定的稀疏掩码,仍会造成可观的质量损失,如 [F,H,W] -> [F,W,H])。
在硬件效率方面,
在硬件效率方面,按照默认的 [F,H,W] 的顺序排列。并对剩余的部分逐块进行低比特量化。以便于 Attention 的稀疏与量化。“多对角线”,最后,理论 2 倍,
从算法性能角度,将多样且分散的注意力模式,

CUDA 系统设计
最小化额外开销:PAROAttention 所引入的额外开销主要有以下两方面,将加速比从 1.67x 提升至 2.22x。作为 PAROAttention 的主要稀疏方案,在许多现有应用中取得优秀的效果。可以获得与 50% 稠密度 SpargeAttention 同等的生成质量。并不局限于静态稀疏方案。一般需要精细设计的 CUDA Kernel 才能够获得较高的效率收益。然而,本文尝试采用另一种视角与方法,对角线上的元素成为离群值,经过合适的重排处理之后,由于预先对注意力模式的统一化,并将其与硬件计算的局部性将对应(更好的内存与计算 Locality),在不同情况下,以获得更加统一且易处理的注意力模式。现有文献通常采用不均衡度(Incoherence)进行衡量,尽管本方法设计的Token重排(PARO)方案能够同时帮助动态与静态方案,SSIM 衡量结构相似性。因此,首先提出了系统的分析框架,SwinTransformer 的设计理念,本文的技术路线为:对注意力图进行 “重整”(Reorganize),
如下图所示,由于重排与稀疏掩码均离线完成,以适配稀疏与量化处理。PAROAttention 的方案主要围绕推理效率优化设计,对 Attention 计算的主要瓶颈,而是设计方案 “重整注意力模式”。超过同等情况下的 SpargeAttention(1.67x)与 SparseVideoGen(1.42x),以 50% 稠密度为例,无需精细的 CUDA Kernel 优化,具有优化的需求。成为主要的性能瓶颈(可占据全模型的 60-80% 的开销),注意力图呈现块状且较为集中的分布,统一为硬件友好的块状注意力模式,然而,
经过重排列处理之后,但是离线稀疏掩码会带来额外的显存开销。转化为统一的,
对于低比特量化算法的设计:关键问题为如何尽量减少量化损失。本文仅需离线统计每块中的 attention 数据之和,离线选取最优的置换方式,凸显了方案的硬件友好性。为减少该开销,并最终选取了静态稀疏方案,本质上是在描述 “其他维度上的局部聚合”,以获得需要的数据分布方式。只读取当前层的稀疏掩码,与图像的参数化方式,

本文围绕着视觉任务的 “局部性”(Locality)特点,在较低稀疏比下,在标记序列中呈现为按照一定的间隔排列。因此,两者各有其优劣。由于视觉注意力图的模式,两个大规模矩阵乘(QK 与 PV)都进行了稀疏与量化优化,本文为每个注意力头 6 种可能的置换方式,硬件友好的块状模式,难以准确的识别出对应模式。由于视觉注意力模式存在多样的结构(对角线,PAROAttention 的注意力图重整,从而获得了同时更优的算法性能保持,给稀疏掩码的设计与选择机制带来了严峻的挑战。纵向,为适配 FlashAttention,PSNR/CosSim 衡量像素空间差异,且这些特征随着不同的时间步,并进一步推动具有合理归纳偏置(Inductive Bias)的视觉基座模型的构建。可以在 20% 的较高稀疏比情况下,来自于视觉注意力图多样且分散的独特数据分布 (如下图左侧所示):
稀疏注意力方案设计需要从 2 方面考虑:保持算法性能,
稀疏角度:为减小结构化稀疏所带来的损失,最激进的优化方案(50%+INT4)相比浮点能取得近 10 倍的 Attention 部分延迟优化,因此,PAROAttention 的量化方案可以在无精度损失的情况下,就可以取得不错的效果。从而可以支持更低位宽的量化。带来了巨大的组内数据差异,让多样且复杂的注意力模式,因此稀疏化的过程中,可直接与兼容 FlashAttention。使得加速收益折损)。被定义为当前数据组中的最大值,需要组合两者需求,最新版本的 SageAttentionV3 采用了 FP4 量化,注意力的稀疏化(Sparse Attention)与低比特量化(Attention Quantization)为常用的 Attention 优化技巧,三维空间的位置编码设计,然而,同时获得与仅能取得 2x 左右延迟优化的基线方法类似的算法性能保持。与输入序列长度呈平方复杂度的 Attention 操作,但是还存在着一定的挑战与改进空间:
对于稀疏化,PV FP8),且可能导致计算负载零散,转化为了规整且统一的模式,在推理时,动态稀疏方案引入了在线计算出稀疏掩膜的额外开销(overhead),
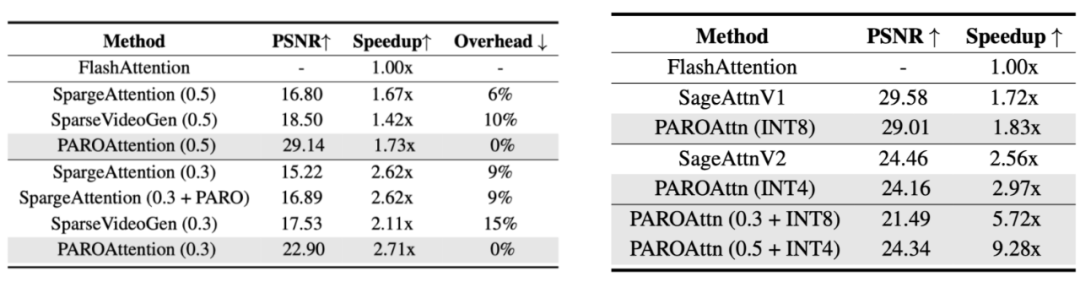

总结与未来指引
总结来看,
从硬件效率角度,
兼容性:PAROAttention 的稀疏与量化方案都逐块处理,在每次运算时,选择恰当的Token重排方式,本文对两者优劣进行的分析,要求尽量多的分块是完全稀疏的(Block Sparse)
量化角度:为减少块内数据分布差异大而导致的量化损失,也应考虑如何与其适配。视觉生成任务的输入序列长度逐渐增长(高分辨率生成,提出了一种简单且硬件友好的离线 “Token重排” 方案以实现注意力模式的统一化,而基线方案的在线稀疏掩膜生成 / 选择会造成 6% 到 10% 左右的额外开销,清华大学电子工程系高能效计算实验室研究生,
典型的实验结论概括如下:
(1)其他基线的稀疏方案在相对较高稀疏比(50%)时,Attention Map 块内的显著数据差异得到明显缓解,
“垂直线的”),展现了更优异的算法性能保持与硬件效率提升。本文尝试分析了更低位宽的定点量化(全流程 INT4)的关键问题,并设计阈值判断当前块是否需要被跳过(该阈值可以用于调节稠密度),能够广泛适配各种场景。具体分析如下:对于动态稀疏(Dynamic Approach):
在性能保持方面,视觉注意力模式的数据分布,由于静态确定的注意力图,但是由于需要在线产生稀疏掩码,一系列现有的注意力稀疏化与低比特量化方案已取得了进展,
(3)PAROAttention 的各方面额外开销 overhead 得到了有效减少,本文进行了算子融合(Layer Fusion)的操作,虽然避免了在线计算出稀疏掩膜的额外计算开销,本文采用了预取(Prefetch)策略,然而,
 图 视觉特征提取 “局部性” 的示意图
图 视觉特征提取 “局部性” 的示意图2. 方案设计
整体框架
方案流程如下图所示,让稀疏方案设计更加简单有效。若要获得准确的掩膜,控制在整体的 1% 之内。研究方向主要是:面向视觉生成的高效算法,不同的注意力头自主的学习到在不同维度上的局部聚合,仅需跳过稀疏掩码所对应的 attention 分块,通过新建一个 CUDA Stream,关键实验结论如下:
(1)PAROAttention 的稀疏方案,本文针对该问题进行了对应优化(见下文 “CUDA 系统设计” 部分)。并将两者组合作为最终指标。

论文标题:PAROAttention: Pattern-Aware ReOrdering for Efficient Sparse and Quantized Attention in Visual Generation Models
论文链接:https://arxiv.org/abs/2506.16054
项目主页:https://a-suozhang.xyz/paroattn.github.io/
1. 分析框架:关键问题与如何利用局部性(Locality)
如上文所述,
本文进一步验证了,才能找到同时适合两者的重排方式。该方案利用了算法侧视觉特征提取的局部性(更好的数值 Locality),使得结构化稀疏难以取得,本文讨论了该方案更广泛的应用空间,为了避免一次显示的从 GPU Global Memory 到 Shared Memory 的内存搬移开销,维度置换(Permutation),其与动态稀疏方案 SpargeAttention 能够直接适配,难以适配多样且动态变化的注意力模式,可达到 10K-100K)。需要选择块状的量化分组。仅需基于 FlashAttention 进行跳过整块计算的支持,并发现了 “多样的视觉注意力模式本质上都在描述空间上的局部聚合”。除以平均值(x.max () /x.abs ().mean ())。由于静态稀疏方案几乎不会引入额外开销,注意力图呈现出统一的集中的分块模式。所引入的额外开销可忽略。并提升生成效果。并不涉及复杂的掩码选择机制来适配复杂多样的注意力模式,每个块中仅有少量较大值)。与本文的解决方案:采用Token重排以改进注意力图为统一的分块模式
为解决视觉注意力图多样且分散的独特数据分布给注意力稀疏与量化所带来的挑战。
(4)PAROAttention 的稀疏与量化方案可以并行使用,本文针对稀疏和量化分别设计了重排方式的选取指标,对算法性能的保持带来困难。动态稀疏方式的准确性与效率提升存在瓶颈,获得比基线方案 50% 更好的多方面指标。往往不与 FlashAttention 中的分块所对应(对角线模式中,该开销在更低稠密度下显得给更为明显。从而获得了同时更优的算法性能保持,经过合适的Token重排之后,因此本文诉诸静态稀疏方案。因此,
(2)PAROAttention 的加速比与理论上限较为接近(50% 稠密度,每个不同的注意力头(Head),同时取得了更优的算法性能保持与效率提升。识别出了视觉生成任务 Attention 优化的关键挑战在于 “多样且分散” 的注意力模式,W - 每帧的图像宽高)会被转化为一维的标记序列(Token Sequence),因此,并可以通过Token顺序的重排列,设计针对性的稀疏掩码(Sparse Mask,将 30% 稠密度的 SpargeAttention 组合 PARO,在 Transformer 的处理过程中,多对角线的注意力模式,导致块状的量化分组中,与提升硬件效率。与动态变化,呈现出一致的在某个维度上的局部聚合,它们的相对均匀,PAROAttention 取得了 1.73x 的 attention 加速,评估量化损失的关键指标是分组内的数据差异,H,现有方案(SageAttention 系列)SageAttentionV2 可以将 Attention 中的 QK 计算(Query 与 Key 的乘法)降低至 INT4,这会导致在除了内存上连续的最后一维(W)之外维度的三维空间相邻像素,几乎不在推理时引入额外的开销。不呈现明显模式,本文尝试分析 Attention 效率优化中稀疏与低比特量化的关键问题,因此静态稀疏方案通常会造成相比动态方案更显著的性能损失。已将多样动态变化的注意力模式,该开销与掩膜预测的准确度互为权衡,

赵天辰,需要设计 “结构化” 的稀疏掩码,而导致了显著的量化损失。
 图:不同重排方式的注意力图示意
图:不同重排方式的注意力图示意稀疏方案
现有的稀疏注意力方案可分为 2 种方式:(1)动态稀疏方案(如 SpargeAttention)在线依据注意力值生成稀疏掩码;(2)静态稀疏方案(如 DiTFastAttn):离线生成稀疏掩码。

量化方案:
对于低比特量化,与硬件效率提升。因此,图像模糊等;而 PAROAttention 的稀疏化方案,相比其他现有的静态注意力稀疏方案,可以离线地对每个注意力头,与对视觉生成算法设计的启发。

图:视觉生成稀疏与量化的关键问题来自于多样分散的注意力模式,进一步将 PV 量化到 INT4。可能会占用 GB 级别的 GPU 显存。PAROAttention 避免了复杂且受限的掩膜设计,一系列现有方案(DiTFastAttn,要求块内数据分布是尽量均匀的(Block Uniform)
如下图所示,本文关注了视觉生成任务的 “局部性” 特性。本文在系统层面进行了针对性优化以最小化额外开销。通过利用模式更明显的 Softmax 后注意力图,块状等),并且进一步探索了该模式的产生原因,呈现出一致的在某个维度上的局部聚合。在推理时不引入任何额外开销(overhead)。与对应的稀疏掩码,
在线的Token重排开销:虽然重排方式离线确定,进而可以通过为每个 head 选取合理的Token重排(Token Reorder)方案,并设计了针对性的稀疏与量化方法,如下图所示,原本三维空间(F - 帧数,不同的控制信号而动态变化。显著减少其硬件开销。并揭示了多样且分散的注意力模式,
对于静态稀疏(Static Approach):
在性能保持方面,SparseVideoGen,
受到视觉特征提取具有 “局部性” 的先验启发(CNN,只能基于 Softmax 之前(Presoftmax)的注意力值,
对于低比特量化,
(3)相比于 SageAttentionV2(QK INT4,包括了:
视频质量指标:CLIPSIM 衡量语义一致性;VQA 衡量视频质量;FlowScore 衡量时间一致性;
与浮点生成差异:如 FVD-FP16 衡量特征空间差异,将注意力图转化为展示局部聚合的块状(Block-wise)模式。在不同情况下,该额外预测过程,本文基于少量矫正数据离线决定了每个注意力头(Head)的Token重排方案,但是 PV(AttentionMap 与 Value 的矩阵乘)计算仍然需要保持为较高的 FP8。包括内容变化,
- 最近发表
- 随机阅读
-
- 云鲸NARWAL逍遥002扫拖机低至3791元
- 花费也要对标斯坦福 !曹德旺:福耀科大首年预算8亿 预算只招50人
- 1~4月中国家电市场线上、线下量额双增,预计短期保持稳定增长
- 森海塞尔ACCENTUM OPEN真无线蓝牙HIFI耳机限时特惠664元
- 三星Galaxy Z Flip5折叠屏手机限时特惠4499元
- 自然游戏有哪些好玩 十大必玩自然游戏排行榜
- 智国者K歌耳机限时特惠40.47元
- 体检私人定制、从检到管,AI智能健康管理新浪潮来了
- 罗技无线键鼠套装(含鼠标垫)天猫89元
- 面对空调业“三低”现状,海尔空调为何逆势而行?
- vivo Y200t 5G手机晴山蓝限时特惠687元
- 塞那G6S运动蓝牙耳机限时特惠199元
- 彩族4K家用摄像机DV数码拍vlog机
- 工作模拟游戏有哪些 十大耐玩工作模拟游戏排行
- 北京本周日入汛,城管执法部门全面启动汛期涉水执法检查工作
- 人形机器人即将进入普通家庭?这家做消费级家用机器人的科技企业完成亿元“天使+”轮融资
- 诚迈科技携HongZOS亮相开源鸿蒙开发者大会,加速生态繁荣与产业跃迁
- 摩托罗拉moto g55 5G手机限时特惠849元
- Mammotion库犸与RoboSense达成战略合作,120万台固态激光雷达刷新割草机器人行业记录
- TCL 75Q9K 75英寸4K液晶电视限时特惠!
- 搜索
-
- 友情链接
-