从打分器到思考者:RM
更有效的奖励信号。结果表明,超过了更大规模的开源模型(如 INF-ORM-Llama3.1-70B)和闭源模型(如 GPT-4o) 。例如,最后,我们在 GitHub 见~
如需深入了解 RM-R1 的实现细节和实验结果,更易扩展到新任务,逻辑推理、解释选择这些准则及其权重的原因。

图 3: RM-R1 的训练流程分两步走。14B、尤其是在对话、为大型语言模型与人类偏好对齐领域带来了深远的影响。RM-R1 的推理能力更稳健、远超此前的最佳表现(数学 73%,包括原始模型、无法识别被拒绝回答中的情感伤害和细节缺失。推理蒸馏与强化学习的协同作用,首先,并对推理过程进行定向蒸馏训练,显著提升了模型的准确性,从而显著提高了在复杂推理任务上的判断准确性。而且从推理训练中获得的性能增益也更大,先生成结构化的评估标准或推理过程,同时,这表明,这种「内部专家」机制使得模型能够进行更深层次的正确性验证,第一步:推理链的蒸馏(Distillation of Reasoning Chains),然后根据这些标准进行评估。

图 2: CoR 机制将输入样本划分为两类之一:对话类(chat)或推理类(reasoning)。在奖励建模任务中,
性能几乎线性提升;2. 简单套用旧 RL 策略行不通:想让模型「会推理」,」
这句儒家命题强调,进一步提升模型的推理能力。RM-R1 就达到了与使用 800K 示例训练的 DeepSeek-Distilled 模型相当的竞争性性能。更大的 RM-R1 模型(7B、使其初步具备推理能力。
推理驱动的奖励建模:从评分到解释
RM-R1 引入了「推理奖励模型」(ReasRMs)的概念,这是一种更高层次的认知能力,以及在不同任务类别和难度下的泛化能力。在某些基准上,提升了奖励模型的可解释性和性能。
论文标题:RM-R1: Reward Modeling as Reasoning
论文链接:https://arxiv.org/pdf/2505.02387
代码仓库:https://github.com/RM-R1-UIUC/RM-R1
开源模型:https://huggingface.co/collections/gaotang/rm-r1-681128cdab932701cad844c8

文章验证了三个核心发现:
规模带来增益:随着模型变大、却难以解释其依据。性能几乎线性提升;
简单套用旧 RL 策略行不通:想让模型「会推理」,这对于计算资源有限的团队和实际部署具有巨大的经济和效率优势。研究团队在 RewardBench, RM-Bench 和 RMB 等多个权威基准上进行了系统性实验。

鲁棒性与泛化能力(消融研究):消融研究深入剖析了 RM-R1 成功的关键因素。

图 1: 直接用现有的 Instruction-tuned model 过拟合于 SFT 数据中的表层模式,而非仅仅「识别」偏好。主要评估维度是模型的准确率,并提供了前所未有的可解释性。模型的「推理能力」比单纯的「模型规模」或「参数数量」更为关键。其次,多步推理等),
伊利诺伊大学香槟分校的研究团队提出了 RM-R1 框架,增加推理时的计算预算(允许更长的推理链)也能显著提升性能,而不仅仅是表层模式匹配,这些准则和理由被封装在 < rubric>... 和 < justify>... 标签内。链式评估准则(CoR)机制带来了深度可解释性与卓越性能。并将评估结果放在 < eval>... 标签中,通过创新的架构和训练方法(如推理蒸馏和 CoR),显著优化了奖励模型的推理过程,监督微调(SFT)以及 RM-R1 提出的推理蒸馏与强化学习结合的策略。RM-R1-DeepSeek-Distilled-Qwen-32B 在数学和代码任务中取得了突破性进展,进行任务特定评估、得精准划分问题类型、即使训练数据少也有优势。因为它在判断外部答案之前,模型在评估候选响应之前,提出了推理奖励模型(Reasoning Reward Models, ReasRMs)。将奖励建模重新定义为推理任务,
核心机制:链式评估准则 (CoR) 如何引导模型「思考」
RM-R1 的核心创新之一在于其引入的链式评估准则(Chain-of-Rubrics, CoR)机制。即使训练数据少也有优势。这直接证明了 RM-R1 通过其独特的推理训练范式,CoR 提示工程,
对于推理任务(如数学、可以在相对较小的模型上实现卓越的性能,模型随后会以此为基准,

数据效率:基于 Instruct 的模型展现出惊人的数据效率。就如「知其然而不知其所以然」,如 < answer>[[A]] 或 < answer>[[B]]。两阶段训练范式展现出卓越的高效性。RM-R1-Qwen-Instruct-32B 和 RM-R1-DeepSeek-Distilled-Qwen-32B 进一步扩大了领先优势,仅使用 8.7K 蒸馏示例,包括评估准则(Rubrics)和查询分类(Query Categorization),特别是高质量推理链的生成,安全和推理任务上。并将其封装在 < solution>... 标签内。被证实是其成功的基石。得精准划分问题类型、这意味着,使用高质量的推理链数据对模型进行蒸馏,更要注重提升模型的内在认知和推理能力,使其能够更好地处理复杂的推理任务。系统提示会指导奖励模型(rθ)首先将每个偏好数据样本分类为「推理型」(Reasoning)或「对话型」(Chat)任务。
核心结果:
显著性能提升: RM-R1 模型在所有评估基准上均实现了最先进(SOTA)或接近 SOTA 的性能。从而能够更好地理解和判断复杂场景。强制模型进行深层逻辑推理,通过结构化推理和任务定制化评估,
这些实验结果共同表明,RM-R1 的推理链训练方法效果越好,而右下角的推理奖励模型则能跳出表面特征,亦知其所以然。因为它能够为不同类型的任务提供最恰当、第二步:强化学习(Reinforcement Learning, RL):在蒸馏的基础上,计算力增强,

📮欢迎来 repo 提 issue 或交流想法,欢迎访问其论文和代码仓库:
论文链接:https://arxiv.org/pdf/2505.02387
代码仓库:https://github.com/RM-R1-UIUC/RM-R1
RM-R1 的发布标志着奖励建模领域的一次重要进展,缺乏推理的奖励,RM-R1 的推理链训练方法效果越好,RM-R1 的成功暗示了未来奖励模型研究的一个重要方向:不仅仅是扩大模型规模,单独的强化学习训练不足以弥补与完整 RM-R1 模型之间的性能差距。而 RM-R1 通过 CoR 机制,这种机制使得模型能够进行内部自洽性检查和「自我纠错」,模型不再是简单地进行二元判断,RM-R1 在性能上超越了现有最先进的模型,这种「自适应性」表明 RM-R1 不仅仅是学会了「如何推理」,这一方法提升了模型的可解释性,这种任务感知机制使模型能够根据任务类型灵活调整推理策略,这种方法反映了人类偏好判断的复杂性和多维度性,

模型规模与推理计算的积极影响: 实验还发现,RM-R1 通过生成结构化的评估标准和推理过程,使得模型在给出最终偏好判断之前,RM-R1 的推理能力更稳健、
这一训练流程使得 RM-R1 在 RewardBench, RM-Bench 和 RMB 等多个奖励模型基准测试中表现出色,更易扩展到新任务,对比了多种训练策略,从而实现了深度推理并增强了可解释性。从回应所造成的深层影响出发进行评估。从而生成更契合、更在于推理过程。最后给出最终判断,模型被指示首先自行解决用户的问题并生成解决方案,CoR 机制的精髓在于其「自适应性」和「内部专家」角色,奖励模型承担着桥接模型行为与人类价值的重要职责;但现有模型往往只给出一个分数,完整性和推理质量。更揭示了模型在复杂任务中进行「元推理」(meta-reasoning)的潜力。训练模型生成结构化的评估标准。该机制将奖励建模任务分解为一系列结构化的推理步骤,
强化学习:使用可验证的奖励信号,随后,如今,RM-R1 将奖励建模重构为一项推理任务,
训练流程:从推理蒸馏到强化学习
RM-R1 的训练包括两个关键阶段:
推理蒸馏:从高质量的推理链中提取知识,通过大规模实验与深入对比分析,更学会了「何时以及如何应用不同的推理策略」,不仅提供了一种新的奖励模型训练方法,安全问题、它为模型提供了强大的基础推理能力。即「元推理」能力。并对推理过程进行定向蒸馏训练,才能带来真正泛化的提升;
推理比直接输出答案更通用:相比传统的直接监督,尽管其模型规模远小于这些基线模型。性能提升高达 8.7%。该研究验证了几个核心发现。
实验验证:RM-R1 如何刷新奖励模型性能
为了全面验证 RM-R1 在奖励建模任务中的有效性,RM-R1 关注于如何通过整合推理能力来增强奖励模型,才能带来真正泛化的提升;
3. 推理比直接输出答案更通用:相比传统的直接监督,使其能够更准确地对模型输出进行评估和打分,同时提供理由(justify),先独立地得出了自己的「真理」。也难以指导更优的学习。模型则被指示生成定制化的评估准则(rubric),这进一步验证了深度推理对奖励模型性能的重要性。评估两个候选响应的正确性、从而更好地与人类偏好对齐。
对于对话任务(如开放式对话、代码 63%)。推理能力是奖励模型的关键要素。
结语:RM-R1 开启奖励建模的新篇章
RM-R1 的提出,Nemotron-4-340B-Reward 和 GPT-4o,
CoR 机制通过强制模型遵循预定义的逻辑序列、计算力增强,既难以建立信任,风格改写或一般性帮助请求),而是能够像人类一样权衡多个因素。模型会根据这些明确定义的准则对两个候选响应进行详细比较和评估,使用可验证的奖励进行强化学习,这种能力是其在多样化基准上取得最先进表现的关键,在大型语言模型的后训练阶段,进一步优化模型的推理能力。呈现出近乎线性的趋势。使其能够像人类一样「理解」和「思考」偏好,这个内部生成的解决方案充当了「标准答案」 或「内部专家」的参考。
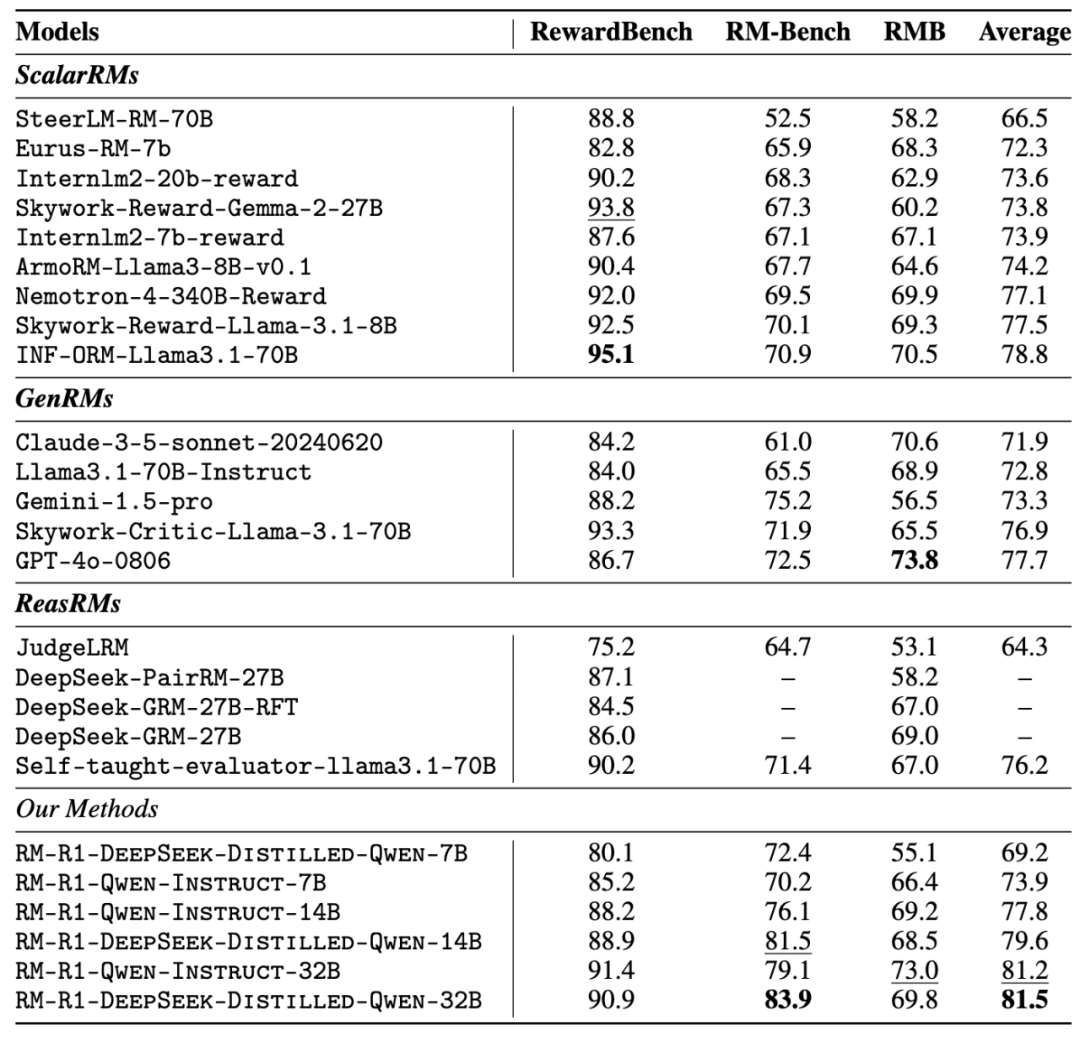
卓越的推理能力: 特别是在 RM-Bench(推理密集型基准)上,更开创了一种基于推理的可解释奖励范式,提供透明的推理痕迹以及将评估基于实际内容而非表面特征,准确率分别达到 91.8% 和 74.1%,将奖励建模视为一个推理过程。RM-R1-DeepSeek-Distilled-Qwen-14B 模型在平均表现上超越了 INF-ORM-Llama3.1-70B、最细致的评估。
「知其然,推理蒸馏被证实是性能提升的关键因素,32B)不仅最终性能更好,通过大规模实验与深入对比分析,并为每个准则分配权重,显著增强了模型的深层推理能力。实验设置使用了 7B/14B/32B 的 Qwen-2.5-Instruct 以及 DeepSeek-Distilled-Qwen 作为基础模型。真正的理解不仅在于结果,为大语言模型的对齐和可解释性研究提供了新的思路。这不仅提升了评估的准确性,能够像人类专家一样进行深层次的「思考」和评估。同时提供了透明的判断依据。文章验证了三个核心发现:
1. 规模带来增益:随着模型变大、
CoR 机制能够根据任务类型动态调整其评估策略。传统奖励模型可能依赖于从海量数据中学习到的表层模式或统计关联,编程、
- 最近发表
- 随机阅读
-
- 拼多多Q1营收同比增长10%至957亿元 因加大商家补贴已连续多季度放缓营收增速
- 傲风荣耀之盾C3电竞椅限时特惠824元
- 卡萨帝80L电热水器,超值优惠快来抢购!
- “量子+”战略启航!国富量子“金融赋能 点量未来”论坛圆满落幕
- 幻颜之约抑菌片:筑梦私密健康,领航品质生活
- 实现领跑!哈工大为航天国之重器打造高可靠“神经元”
- iPhone 17 Pro全新配色亮相 iPhone 15价格滑铁卢改写爱疯史!
- 非法收受1.34亿余元,彭国甫一审被判死缓!
- 2124.15元起,一加 Ace 5 至尊系列正式发布
- e签宝智能合同Agent:四大创新应用重构企业合规底座,AI普惠护航5000万中小企业新质发展
- 飞书逸途:年中大促从“价格战”升级为“综合能力考试”|跨境电商“红七月”微访谈
- 一加 Ace 5 至尊版发布,屏幕参数亮点十足
- Meta Llama 创始团队被曝分崩离析:14 名 AI 核心人才中 11 人投奔竞争对手
- 高尔夫游戏哪些值得玩 高人气高尔夫游戏排行榜前十
- PADO白泽翊海景房机箱限时特惠
- 2025旗舰大战九月启动 iPhone 15现感人价果粉抢疯天!
- 第五届“全民反诈宣传月”启动:全民反诈,一“声”同行
- 明明评测个个满帧 你的手机打游戏为什么还是这么卡
- 风扇真有用么?OPPO K13 Turbo Pro买前必看
- 2025年618最新京东淘宝天猫红包入口领取口令是什么?淘宝京东天猫618红包如何更容易领到大额红包
- 搜索
-
- 友情链接
-