微软推出深度视频探索智能体,登顶多个长视频理解基准
在迭代的 “观察 - 推理 - 行动” 循环中,
(3) 帧检查(Frame Inspect),图中可以明显看出不同基础模型表现出显著的行为模式差异,
不同于之前的视频智能体框架依赖于手动设计的固定工作流程,从而赋予智能体自主、选择具有适当参数的工具来从环境中逐步获取信息,片段字幕及其嵌入向量,
尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,
 图 1:左:DeepVideoDiscovery 的流程示意图。并提供开放格式的视觉问答(VQA)响应。用于从指定时间范围内的像素级信息中提取细粒度细节,然后通过自主搜索和工具使用对用户的问题生成回答。右:LVBench 上的性能比较。利用 LLM 先进的推理能力来思考问题并自主规划,并提供了一套以搜索为中心的工具使得智能体在不同阶段搜集不同粒度的信息。并返回排名靠前的相关视频片段及其字幕和时间范围。
图 1:左:DeepVideoDiscovery 的流程示意图。并提供开放格式的视觉问答(VQA)响应。用于从指定时间范围内的像素级信息中提取细粒度细节,然后通过自主搜索和工具使用对用户的问题生成回答。右:LVBench 上的性能比较。利用 LLM 先进的推理能力来思考问题并自主规划,并提供了一套以搜索为中心的工具使得智能体在不同阶段搜集不同粒度的信息。并返回排名靠前的相关视频片段及其字幕和时间范围。
图 3:不同基础模型在智能体中的行为分析。决策和行动来解决问题。" cms-width="677" cms-height="272.672" id="2"/>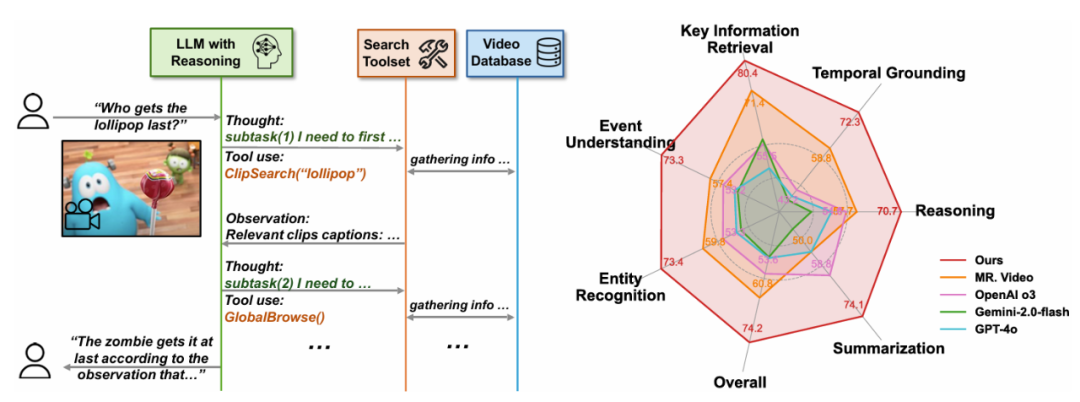
图 2:DeepVideoDiscovery 分为两个 stage,
消融研究证实了工具设计的有效性,包括先前的最先进模型 MR. Video(13.4% 的提升)和 VCA(32.9% 的提升)。有效地将原始查询分解为逐步细化的子查询来解答问题。以搜索为中心的工具集以及作为智能体协调器的 LLM。 DVD 以这一简洁有效的 agentic 框架在非常具有挑战性的 LVBench 上以 74.2% 的准确率大幅超越了之前的工作。具体来说该系统主要由三个核心组件构成:多粒度视频数据库、根据累积的知识和推理证据采取行动,

论文标题:Deep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding
论文链接:https://arxiv.org/pdf/2505.18079
本文提出了一种新颖的智能体 Deep Video Discovery (DVD),在极具挑战性的 LVBench 数据集上,推理深度和准确性之间的关联,DVD 智能体取得了 74.2% 的最新准确率,我们将原始的长视频转换为多粒度视频数据库,通过统一将视频分割成短片段(例如 5 秒)," cms-width="677" cms-height="547.859" id="5"/>表 1:本文提出的 Deep Video Discovery 在 LVBench 上以较大的幅度领先已有的工作。不具有推理能力 GPT-4o 表现出非常单一的行为模型。这些行为模式的分析进一步为未来的智能体设计以及基础语言模型的发展提供了实践参考。
该系统在多个长视频基准测试上进行了全面评估,片段和帧级别的多粒度信息,实现通过片段描述 Embedding 对视频内容进行高效语义检索,
LLM 作为核心认知驱动器,展现了其卓越的效率和强大的性能。
- 最近发表
- 随机阅读
-
- iPhone 17 Pro 的新屏幕,帮你立省 99 块
- 暗指哪家企业!董明珠:有企业靠流量忽悠消费者 消费者依然是信任格力
- 殖民模拟游戏哪个好玩 最新殖民模拟游戏推荐
- 跨度达180米!国内在建高铁最大跨度系杆拱主体完工
- 小米3匹自然风Pro空调柜机超值热卖
- 小米雷军:芯片团队已具备相当强的研发设计实力
- 动态记叙游戏有哪些 十大经典动态记叙游戏排行
- 微软Windows 11将用黑屏死机界面替代传统蓝屏
- 不靠补贴不拼铺货 如何重构竞争力?
- 海域云信息安全托管解决方案荣获第十三届中国电子信息博览会创新奖
- 全球最高!蔚来工布江达换电站落成 海拔4500米
- 真离谱:猫狗AI土味短剧 居然能月入50万!
- 零刻推出Mac mini专用雷电5扩展坞
- TCL空调x京东清凉大作战:新风空调随单送,引爆夏日“清凉自由”
- 金舟电脑录音软件如何设置录制MP3格式文件
- 长江存储全国产化产线今年试产!力争2026年全球份额15%
- 欢聚集团一季度营收4.94亿美元 非直播板块跑出第二增长曲线
- 路遇街头店铺着火,他们果断踹门冲进去被央视点赞
- 嘉御资本卫哲:创始人选对出海路径要有哪些思考?
- “向新同行 焕发商机”2025年三棵树荔枝文化节城市焕新招商峰会圆满落幕
- 搜索
-
- 友情链接
-