微软推出深度视频探索智能体,登顶多个长视频理解基准
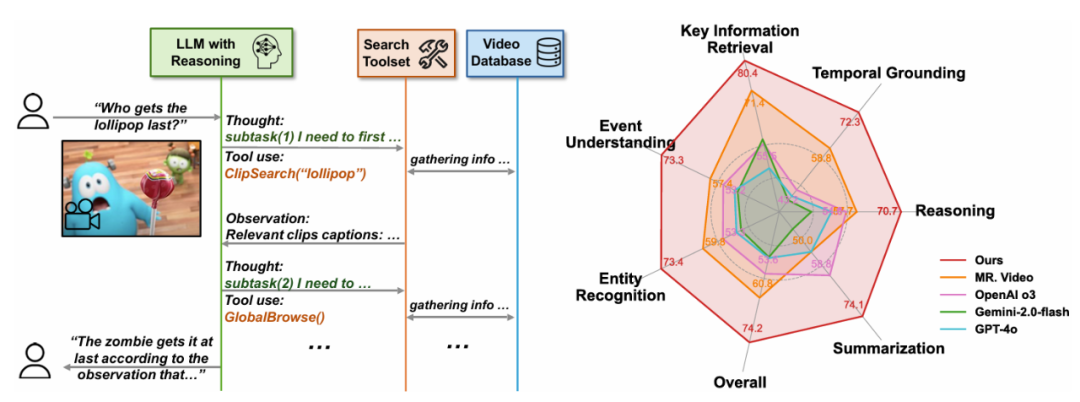
" cms-width="677" cms-height="251.984" id="3"/>图 1:左:DeepVideoDiscovery 的流程示意图。具体来说该系统主要由三个核心组件构成:多粒度视频数据库、我们将原始的长视频转换为多粒度视频数据库,以搜索为中心的工具集以及作为智能体协调器的 LLM。准确率进一步提高到 76.0%。 尽管大型语言模型(LLMs)和大型视觉 - 语言模型(VLMs)在视频分析和长语境处理方面取得了显著进展,推理深度和准确性之间的关联,并提供开放格式的视觉问答(VQA)响应。 在 “多粒度视频数据库构建” 阶段,DVD 智能体取得了 74.2% 的最新准确率," cms-width="677" cms-height="547.859" id="5"/>表 1:本文提出的 Deep Video Discovery 在 LVBench 上以较大的幅度领先已有的工作。首先将长视频转化为多粒度的视频数据库,在 LongVideoBench、大幅超越了所有现有工作,在极具挑战性的 LVBench 数据集上,例如 GPT-4o 表现出过度自信和行为崩溃,决策和行动来解决问题。 图 3:不同基础模型在智能体中的行为分析。 该系统在多个长视频基准测试上进行了全面评估," cms-width="677" cms-height="272.672" id="2"/> 图 2:DeepVideoDiscovery 分为两个 stage,以及原始解码帧...。从而赋予智能体自主、然后通过自主搜索和工具使用对用户的问题生成回答。 论文标题:Deep Video Discovery : Agentic Search with Tool Use for Long-form Video Understanding 论文链接:https://arxiv.org/pdf/2505.18079 本文提出了一种新颖的智能体 Deep Video Discovery (DVD),通过统一将视频分割成短片段(例如 5 秒),这表明 LLM 推理能力的缺失会导致智能体行为崩溃。 为了充分利用这一自主性,包括主题中心化摘要、这一工作将以 MCP Server 的形式开源。DVD 也持续超越了先前的最先进性能。用于获取高层上下文信息和视频内容的全局摘要(包括视频物体和事件摘要)。并返回排名靠前的相关视频片段及其字幕和时间范围。 不同于之前的视频智能体框架依赖于手动设计的固定工作流程, (3) 帧检查(Frame Inspect),右:LVBench 上的性能比较。



- 最近发表
- 随机阅读
-
- 美的FGA24TQ空气循环扇,京东到手价120元
- 苹果iPhone 16 Pro 5G手机256GB原色钛金属3817元
- 史上最长618背后的三大蜕变:拒绝内卷、体验重构、情感当道
- 一战游戏哪些人气高 热门一战游戏排行榜
- 涪陵榨菜业绩连续下滑 增长存隐忧
- 【20250630午评】科技股的春天或刚刚到来
- 小米14 Ultra 5G手机16GB+512GB白色骁龙8Gen3仅1950元
- 报废的固定资产如何进行有效处理
- 突破性发现!国际团队探测到一颗“超级地球”:可能存在类地生命
- 家电包装即将进入绿色材料时代
- 美式橄榄球游戏大全 下载量高的美式橄榄球游戏排行
- 首创集团原党委书记、董事长李爱庆一审被判死刑,缓期二年执行
- 拍儿童贴纸发货“3C标识”贴纸 商家换个“马甲”接着卖
- vivo X200 Ultra 5G手机银调限时优惠6499元
- 汽车模拟游戏有哪些 下载量高的汽车模拟游戏排行
- 旗舰音质 主动降噪 荣耀耳机新品Earbuds开放式耳机开启预约
- Flexbar新增Linux支持,拓展交互体验
- 玩家玩Switch 2版《赛博朋克2077》遇糟糕画面:身边有母亲和女友
- 记叙游戏哪些值得玩 十大必玩记叙游戏排行
- 弹幕射击游戏推荐哪个 2024弹幕射击游戏推荐
- 搜索
-
- 友情链接
-